Rデータ構造と基本的な記法
RのユーザインタフェースはExcelの対極にあるように見える。しかし実際にはExcelと似ている。
Excelではセルにデータを保存するところを変数を使うというのが最大の違いである。
ただ変数には
- 単一データ(スカラー)
- 一列の複数データ(ベクトル,因子)
- 複数列データ(行列、配列)
- 列単位で異なるデータ型のまとまり(データフレーム)
- さまざまな型データをまとめたもの(リスト)
といった様々な型があり、その都度使い分ける必要がある。そこがExcelよりも柔軟でありかつ難しいところである。
Rのデータ構造(概要)
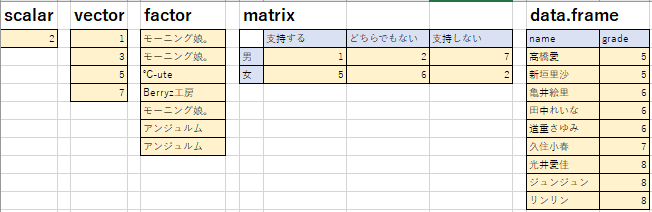
- スカラー(scalar)
-
単一データ
a <- 1 + 1
- ベクトル(vector)
-
単一の型の一次元データ集合(A1:A4)
vec <- c(1,3,5,7)
- 因子(factor)
-
一次元カテゴリデータの集合
group <- factor(c("モーニング娘。","モーニング娘。","℃-ute","Berryz工房","モーニング娘。","アンジュルム","アンジュルム")) - 順序付き因子(order)
-
順序付きの一次元カテゴリデータの集合
group <- ordered(c("モーニング娘。","モーニング娘。","℃-ute","Berryz工房","モーニング娘。","アンジュルム","アンジュルム"),levels=c("モーニング娘。","Berryz工房","℃-ute","アンジュルム")) - 行列(matrix)
-
単一の型の二次元データ集合
mat <- matrix(c(1,5,2,6,7,2),nrow=2,ncol=3) rownames(mat) <- c("男","女") colnames(mat) <- c("支持する","どちらでもない","支持しない") - 配列(array)
-
単一の型の多次元データ集合。一般的な言語の「配列」とは意味が異なるので注意。
arr <- array(c(1,5,2,6,7,2,3,5,6,1,8,2,3,1,5,3,5,3,4,7,3,2,1,0),dim=c(3,2,4))
- データフレーム(data.frame)
-
いわゆるデータベース型のデータ。列単位で同一データ型。
ファイル読み込み時のデータ型。
member <- data.frame(name=c("高橋愛","新垣里沙","亀井絵里","田中れいな","道重さゆみ","久住小春","光井愛佳","ジュンジュン","リンリン"),grade=c(5,5,6,6,6,7,8,8,8)) - リスト(list)
-
複数のデータ型をぶち込める一次元データ集合
hello <- list(group.name=group,morning.member=member)
Rの基本的な記述
- 基本記法
-
2 + 3 #2 + 3の結果を画面に出力 a <- 2^3 #2の3乗の結果を変数aに代入 a #変数aを画面上に出力
- 関数
-
vec <- c(1,3,6,99) #ベクトル・リストを作る vec <- seq(2,10,3) #2から10までの間に3ごとの数列(ベクトルデータ)を作る sum(vec) #合計を求める(SUM) mean(vec) #平均値を求める(AVERAGE) max(vec) #最大値を求める(MAX) min(vec) #最小値を求める(MIN) median(vec) #中央値を求める(MEDIAN) mode(vec) #引数の型を返す(TYPE ×MODE) length(vec) #データ数を求める(COUNTA) print(a <- 1 + 1) #画面に出力する
- 外部データ(csvファイル)の読み込み
-
data <- read.table("filename",header=T,sep=",") #1行目を項目名(ヘッダー)として、カンマ(,)区切りデータを読み込む。ファイルは作業用ディレクトリからの相対パス指定 data <- read.table(file.choose(),header=T,sep=",") #ファイル選択画面からデータファイルを選択する。 data <- read.csv(file.choose()) #定型的なcsvファイルを読み込む場合はheader=T,sep=","を省略できる。※ここで読み込まれたdataはデータフレーム型である。
関数を作る
関数名 <- function(仮引数){
具体的な処理の中身
return(戻り値)
}
作成例:標本分散を求めるvar.p関数
#標本分散を求めるvar.p関数
var.p <- function(x){
varp <- sum((x - mean(x))^2)/length(x)
return(varp)
}
#データを作成
mat <- matrix(1:12,nrow=3)
#var.p関数を実行
var.p(mat)