一元配置要因分散分析
- 本章で用いる実習用ファイル
多グループの平均差
スマートフォン利用増大に対してB大学は対策に苦慮している。今問題となっているのはその対策を学部ごとに違ったものにするのが良いのか、大学全体として一律の対策をするのが良いのか、である。そこで学生の中から500人を無作為抽出を行い、スマートフォン利用時間について調べた。このデータからスマートフォン利用時間に関する学部差を知りたい。
下記データより、B大学の学生のスマートフォン利用時間について、学部間の違いについてデータから得られる知見を述べよ。
| C | D | E | F | G | |||
|---|---|---|---|---|---|---|---|
| 1 | faculty | time | 因子偏差平方 | 残差偏差平方 | 全体偏差平方 | ||
| 2 | science | 193 | |||||
| 3 | law | 166 | |||||
| 4 | science | 293 | |||||
| 5 | social | 215 | |||||
| μ国B大学スマートフォン利用時間調査データ | |||||||
- faculty(名義尺度)
- C2:C501
- time(比例尺度)
- D2:D501
| science | law | social | literature | agriculture | economy |
|---|---|---|---|---|---|
| 205.32 | 169.44 | 180.85 | 171.36 | 194.70 | 178.36 |

この結果より、学部と利用時間との間にどのような関係を読み取ることが出来るだろうか?
学部によって随分利用時間にばらつきがあるようにも見えるが、これも偶然で済ませられる誤差の範囲?それとも必然?
Fisher分散分析( 形式)
形式)
独立した2グループ間での平均差の検定では2グループの平均差を検証したが、今度は3つ以上のグループでの平均差を検証したい。
基本的にやりたいことはt検定と同じだが、3グループ以上になると平均差の計算が出来ない。
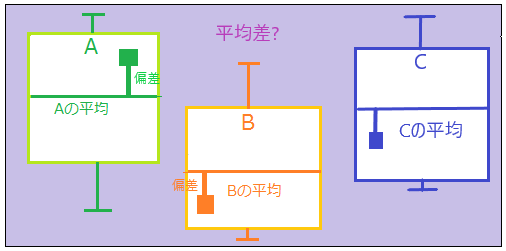
そこで全体の平均とグループごとの平均との差を考える。この平均差がサンプルのばらつき(誤差)より十分に大きければ、グループごとの平均差に意味がある、ということになる。
平均値と個々のデータとの差は分散によってその大きさを測ることが出来る。ということで分散の大きさによって平均差の有意性を検証しようとするのがこの分散分析である。
一般的な分散(全体分散)を二つの分散に分解する。一つはStudentのt検定で用いられた共通分散=グループ内部での分散(残差分散)、もうひとつはグループ間の分散(因子分散)である。
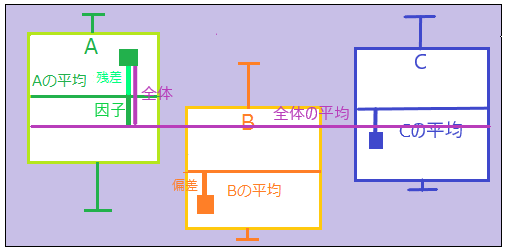
- 因子分散(グループ間)
- 全体の平均と各グループの平均とのばらつき
- 残差分散(グループ内)
- 各グループの共通分散
- Aの平均値からのA内の個々のデータ
- Bの平均値からのB内の個々のデータ
- Cの平均値からのC内の個々のデータ
- 全体分散
- 全体の平均と個々のデータとのばらつき
グループ間の分散が大きいというのは、グループごとの平均値が相互に離れているということである。ということでグループ間の分散を計算する。
- グループ間偏差平方を計算する。
個々のデータについて、自分が所属する学部の平均と全体の平均との偏差平方を求める。
C E 1 faculty グループ間(因子)偏差平方 2 science =(XLOOKUP(faculty,I2#,L2:L7)-L8)^2 3 law 4 science 5 social ※検索関数についてはリンク先で自習せよ。
グループごとの基本統計量 I J J L M 1 N df mean u2 2 science 150 149 205.32 3076.57 3 law 80 79 169.44 1222.63 4 social 60 59 180.85 5744.67 5 literature 80 79 171.36 4844.44 6 agriculture 50 49 194.70 3726.95 7 economy 80 79 178.36 560.97 8 全体 500 499 185.83 3223.81 ※条件付き集計(N:COUNT, mean:AVERAGE, u2:VAR.S)を行う(リンク先の説明を熟読して、式を立てること)。
- グループ内偏差平方を計算する。
個々のデータについて、自分の値と自分が所属する学部の平均との偏差平方を求める。
C D F 1 faculty time グループ内(残差)偏差平方 2 science 193 =(time-XLOOKUP(faculty,I2#,L2:L7))^2 3 law 166 4 science 293 5 social 215 I J J L M 1 N df mean u2 2 science 150 149 205.32 3076.57 3 law 80 79 169.44 1222.63 4 social 60 59 180.85 5744.67 5 literature 80 79 171.36 4844.44 6 agriculture 50 49 194.70 3726.95 7 economy 80 79 178.36 560.97 8 全体 500 499 185.83 3223.81 - 全体偏差平方を計算する。
個々のデータについて、自分の値と全体の平均との偏差平方を求める。
D G 1 time 全体偏差平方 2 193 =(time-AVERAGE(time))^2 3 166 4 293 5 215 - 各々の偏差平方和(変動)を求める。
I J 11 因子 偏差平方和 12 グループ間 =SUM(E2#) 13 グループ内 =SUM(F2#) 14 全体 =SUM(G2#) - 各々の自由度を求める。
I J K 11 因子 偏差平方和 自由度 12 グループ間 105103.77 =COUNTA(I2#)-1 13 グループ内 1503579.45 =COUNT(time)-COUNT(L2:L7) 14 全体 1608683.22 =COUNT(time)-1 - 各々の分散を求める。
I J K L 11 因子 偏差平方和 自由度 分散 12 グループ間 105103.77 5 =J12:J14/K12:K14 13 グループ内 1503579.45 494 14 全体 1608683.22 499 - グループ間分散(因子分散)とグループ内分散(残差分散)の比(F値)を求める。
I L K 11 因子 分散 F 12 グループ間 21020.75 =L12/L13 13 グループ内 3043.68 14 全体 3223.81 グループ間分散が大きくなればなるほどF値は大きくなり、グループの違いによる平均差が偶然では生じにくくなる。逆にグループ間分散が小さくなればF値は0に近づき、グループの違いによる平均差は偶然による誤差に飲み込まれる。この場合平均差に対するグループの違いの意味は小さくなる。
- グループ間分散がグループ内分散より大きい値を取る確率p値を求める。
I K M N 11 因子 自由度 F P(グループ間>グループ内) 12 グループ間 5 6.91 =1-F.DIST(M12,K12,K13,TRUE) 13 グループ内 494 14 全体 499 グループ間の分散(因子分散)が誤差由来のグループ内部での分散(残差分散)に比べて十分に大きければ、グループ同士の平均値は離れていると言える。このグループ間の分散(因子分散)とグループ内部での分散(残差分散)との比をF検定で検証する。
- 帰無仮説-「因子」が違うことは値の違いに無関係である(グループ間で平均に差があるのは偶然だ)
- 対立仮説-因子によってこそ変動(平均からのズレ)は左右されているのであって、残差など文字通りのこりカスや!
- 因子による分散>>(圧倒的な、偶然とかケチの付けようのない差)>>残差による分散
F値が大きくなれば有意と一方向の検定なので片側検定である。
- 効果量η2を求める。
I J O 11 因子 偏差平方和 η2 12 グループ間 105103.77 =J12/J14 13 グループ内 1503579.45 14 全体 1608683.22 効果量η2 効果の目安 0.14 大 0.06 中 0.01 小 0 なし
| 要因 | 偏差平方和 | 自由度 | 分散 | F | p値(因子>残差) | η2 |
|---|---|---|---|---|---|---|
| 因子(因子間) | 105103.77 | 5 | 21020.75 | 6.91 | 0.00% | 0.07 |
| 残差(因子内) | 1503579.45 | 494 | 3043.68 | |||
| 合計 | 1608683.22 | 499 | 3223.81 | |||
t検定との比較
2グループで分散分析を行うとStudentのt検定と同じ結果が得られる。
| I | J | K | L | M | N | O | |||
|---|---|---|---|---|---|---|---|---|---|
| 7 | 要因 | 偏差平方和 | 自由度 | 分散 | F | p値(因子>残差) | η2 | ||
| 8 | 因子(因子間) | 56914.73 | 1 | 56914.73 | 18.27 | 0.00% | 0.04 | ||
| 9 | 残差(因子内) | 1551768.49 | 498 | 3116.00 | |||||
| 10 | 合計 | 1608683.22 | 499 | 3223.81 | |||||
| G | H | I | |||
|---|---|---|---|---|---|
| 13 | 有意水準 | 5% | |||
| 14 | 平均差 | -21.34 | |||
| 15 | 共通分散 | 3116.00 | |||
| 16 | 標準誤差 | 4.99 | |||
| 17 | t値 | -4.27 | =H17^2 | ||
| 18 | 自由度 | 498 | |||
| 19 | p値(≠) | 0.00 | |||
| 20 | p値(>) | 1.00 | |||
| 21 | p値(<) | 0.00 | |||
| 22 | 信頼上限 | -11.53 | |||
| 23 | 信頼下限 | -31.16 | |||
| 24 | 効果量d | -0.38 | |||
| 25 | 効果量r | 0.19 | |||
t検定におけるt値を2乗したものがF値となる。逆にF値からはt値の符号は出てこない。つまりt検定における片側検定に相当することは出来ない。したがって2グループのときにはt検定の方が用いられる(機能が多い)。
この分析方法をFisherの分散分析と呼ぶ。
なおこの分析は各グループが等分散であることを前提とした分析であるため、グループ間の分散の違いに対しては脆弱である(Studentのt検定相当)。
Welch修正(形式)
Fisherの分散分析に対して、各グループが非等分散であることに関して頑健性をもたせたものがWelchの修正分散分析(「平均値同等性の耐久検定 Robust Tests of Equality of Means」)である(t検定におけるStudentとWelch修正の関係と同じ)。実際の分析にはこのWelch修正を用いるのが良い。
計算の中身は理解不能。
- 検定統計量F ← SUM(グループ別サンプルサイズ/グループ別分散*(グループ別平均-SUM(グループ別サンプルサイズ/グループ別分散*グループ別平均)/SUM(グループ別サンプルサイズ/グループ別分散))^2)/(因子自由度*(1+2*(因子数-2)/(因子数^2-1)*SUM((1-グループ別サンプルサイズ/グループ別分散/SUM(グループ別サンプルサイズ/グループ別分散))^2/グループ別自由度)))
- 因子自由度 ← グループの数 - 1
- Welchの自由度 ← (因子数^2-1)/(3*SUM((1-グループ別サンプルサイズ/グループ別分散/SUM(グループ別サンプルサイズ/グループ別分散))^2/グループ別自由度))
- p値 ← 1 - F.DIST(F, 因子自由度, Welchの自由度, TRUE)
| F | G | H | I | J | K | |||
|---|---|---|---|---|---|---|---|---|
| 11 | F | 因子数 | 因子自由度 | 自由度 | p値(因子>残差) | |||
| 12 | Welch | 8.40 | 189.74 | =1-F.DIST(G12, I12, J12,TRUE) | ||||
Excelでこの計算をするのは辛いので、実際の運用にはRを用いるとよい。
課題:
分散分析の結果から得られた知見をまとめよ。
-
スマートフォン利用に対する対策は学部ごとの特性を生かしたものにするのが妥当である。調査よりスマートフォンの利用時間は学部により差がある(F(5,189.74)=8.40, p<.05, η2=0.07)1)。学部ごとのスマートフォンの平均利用時間は図表1の通りである。これほど学部ごとに利用時間に差がある状況で学部横断的に一律な対策を採るのは困難であると考えられる。
図表1:学部別利用時間平均値 science law social literature agriculture economy 205.32 169.44 180.85 171.36 194.70 178.36 
- Welchの修正分散分析による。