R基本統計量
基本統計量の出力はヒストグラム・箱ひげ図の描画には個別に関数が用意されているが、一気に出力するのは手間がかかる。そこで前回取り込んだスクリプトを使ってみる。
とあるグループの身長と年齢データ(excelCrossTab01.csv)を用いる。
関数の入力には補完機能(tabキー)を適宜用いると良い。
基本統計量とヒストグラム
身長を5cm区切りで設定する。
Rスクリプト
data <- read.csv("http://kyoto-edu.sakura.ne.jp/weblesson/office/lesson/excel/excelCrossTab01.csv", fileEncoding = "utf-8")
summary(data)
value <- data$身長
#身長のヒストグラムと度数分布表
start <- 140 #ビンの開始位置
width <- 5 #ビンの幅
source("http://kyoto-edu.sakura.ne.jp/weblesson/statistics/socialStatisticsBasic.R", encoding="UTF-8")
output.descriptive <- descriptive(value,start,width)
#ファイルへの書き出し
write.output(output.descriptive,"output.descriptive.csv")
descriptive関数(socialStatisticsBasic.Rで読み込まれる自作関数)
- descriptive(value,start,width,right,col)
-
- value=基本統計量を算出したい間隔・比例尺度のベクトルデータ (例) c(1,3,2,6)
- start=ヒストグラムビンの開始位置(省略時はxの最小値)
- width=ヒストグラムビンの幅(省略時はスタージェスの公式による)
- right=FALSE→区切りを[以上~未満]で設定する;TRUE→区切りを[より大きい~以下]で設定する(省略時はFALSE)
- col=棒の色(省略時はroyalblue)
出力結果
$statistics
statistics
N 122.000000
mean 157.802459
median 157.000000
mode 157.500000
max 182.000000
min 145.000000
range 37.000000
V 29.927945
sd 5.470644
u2 30.175283
u 5.493203
Missing value 0.000000
$freq
freq
140.00 0
145.00 3
150.00 35
155.00 41
160.00 30
165.00 11
170.00 1
175.00 0
180.00 1
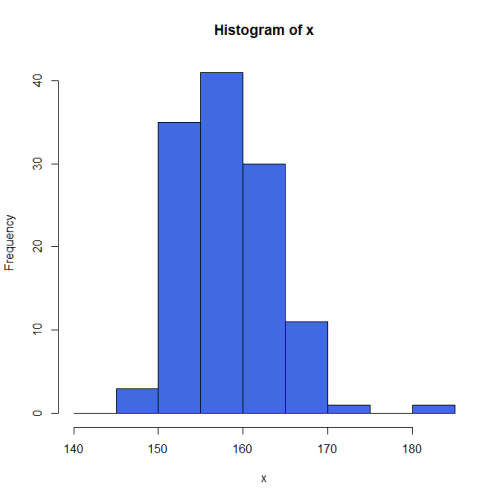
- Vとsdは定義上の(標本)分散と(標本)標準偏差である。spssで求められる(不偏)分散と標準偏差はu2,uである。
- SPSS(やExcelのFrequency関数)とヒストグラムの形が違うのは、区切り幅を[以上~未満]で設定しているためである(SPSSでは[より大きい~以下])。
- SPSSでは最頻値の計算はされない。Excelのmode関数は区切りを設定せず、単に同じ数値の頻度を見ているだけなので、実質使い物にならない。
本スクリプトでは度数分布表でもっとも度数の大きい区間(155~160)の中央値(157.5)を最頻値としている。
グループ別基本統計量と箱ひげ図
グループごとにデータの平均や分布・散らばりを比較したい時にはヒストグラムよりも箱ひげ図が便利である。
Rスクリプト
data <- read.csv("http://kyoto-edu.sakura.ne.jp/weblesson/statistics/data/height-age.csv", fileEncoding = "utf-8")
summary(data)
value <- data$身長
group <- factor(data$グループ) #因子型にする
#グループ別基本統計量と箱ひげ図
output.descriptive.grouping <- descriptive.grouping(value~group)
#ファイルへの書き出し
write.output(output.descriptive.grouping,"output.descriptive.grouping.csv")
descriptive.grouping関数(socialStatisticsBasic.Rで読み込まれる自作関数)
- descriptive.grouping(formula,col)
- formula=「従属変数~因子」の形式で記述する。
- 従属変数=基本統計量を算出したい間隔・比例尺度変数
- 因子=グループ化変数(カテゴリ変数)
- col=棒の色(省略時はdarkorange)
出力結果
$summary
N mean u2 min max median Missing value
Berryz工房 8 161.7500 94.78571 150.0 182.0 160.0 0
BEYOOOOONDS 12 158.5667 34.61697 150.0 168.0 158.0 0
℃-ute 8 158.8000 41.74857 152.0 170.0 157.0 0
Juice=Juice 9 159.1444 16.66278 153.3 165.0 160.0 0
アンジュルム 18 158.3333 20.11765 152.0 166.0 159.5 0
カントリー・ガールズ 6 152.5000 9.10000 148.0 157.0 152.5 0
こぶしファクトリー 8 157.2500 25.85714 150.0 163.5 157.5 0
つばきファクトリー 9 158.5444 20.18278 153.0 167.0 159.0 0
モーニング娘。 44 156.8750 25.03634 145.0 168.0 156.0 0
Sum 122 157.8025 30.17528 145.0 182.0 157.0 0
