χ2分布と母分散に関する検定
ある集団から500人無作為抽出して得られた標本年齢データを用いる。
関西圏を中心に全国規模で展開しているある高齢者向けサービスでは会員の平均年齢は57.00歳であり、年齢の分散は36.91である。このたびD県にて新たにサービスを開始することになり、新規会員を募った。その新規加入者から500人を無作為抽出し、年齢を調べた(設定は架空)。
- 今回標本から得られた年齢の分散(V)は39.79である。全会員の年齢の分散よりも分散が大きいとなるとマーケティングのターゲットが十分に絞り込めていないことになるが、今回の新規会員年齢の分散についてどう判断すべきか。
ある集団の分散(データごとの散らばりの平均)が基準となる分散とは異なっているかどうかを検証したい。
「データが本来あるべき散らばり」(比較対象の分散)に対して標本の散らばり(偏差平方)がどれだけ離れているかをデータ一件ごとに見ていく。データ一件ごとに偏差平方と比較対象の分散の比を取る。
data <- read.csv("http://kyoto-edu.sakura.ne.jp/weblesson/statistics/data/age.csv", fileEncoding = "utf-8")
age <- data$年齢
sigma2 <- 36.91 #母分散
N <- length(age) #サンプルサイズ
squares <- (age - mean(age))^2
v.rate <- squares / sigma2
chisq.value <- sum(v.rate)
| mean | sigma2 |
|---|---|
| 57.56 | 36.91 |
| age | squares | v.rate |
|---|---|---|
| 62 | 19.71 | 0.534131688 |
| 60 | 5.95 | 0.161310284 |
| 66 | 71.23 | 1.930044387 |
| … | ||
χ2値
ここで偏差平方と分散の比の平方根は元の年齢データを標準化(データを平均を0、標準偏差を1になおしたもの)したものに他ならない。つまりこの値は原理的には標準正規分布に従う。
標準正規分布に従う値の二乗和した値をχ2値と呼び、正規分布由来のχ2分布を取ることが知られている。χ2分布は確率分布(距離と確率の関係が既知)の一つである。
自由度
ここでのχ2値は個々の偏差平方と分散の比をデータの大きさN個足したものである。その大本となるデータは観測値である(計算によっては導かれない)N個の年齢データであるが、偏差平方を求める際にその観測値の平均を用いている。つまりデータの前提に一つ計算によって求めたものを含んでいるので、もはやこのデータにはN個の価値はない。観測値としての価値を持っているのはN-1個となる。このときこのN-1を自由度と呼ぶ。
χ2分布
χ2分布はこの自由度により形を変える。このため確率分布関数pchisq(ExcelではCHISQ.DIST)では検定統計量χ2値と自由度を引数とする。
curve(dchisq(x,df=1),from=0,to=20,lwd=3,col=1) #黒 curve(dchisq(x,df=2),from=0,to=20,lwd=3,add=T,col=2) #赤 curve(dchisq(x,df=3),from=0,to=20,lwd=3,add=T,col=3) #緑 curve(dchisq(x,df=5),from=0,to=20,lwd=3,add=T,col=4) #青 curve(dchisq(x,df=10),from=0,to=20,lwd=3,add=T,col=5) #水色
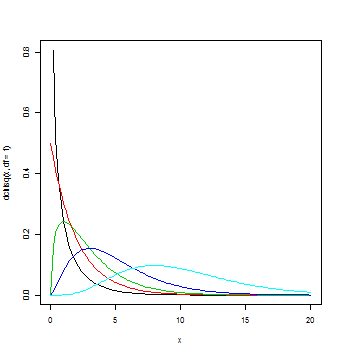
さらに自由度を増やすと
curve(dchisq(x,df=50),from=0,to=100,lwd=3)
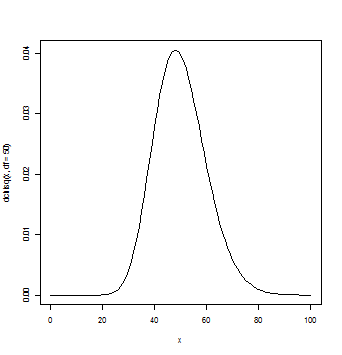
自由度が大きくなればχ2分布は正規分布に近似する。
χ2検定
分布の形はさておき、χ2分布においても距離と確率の関係が分かっていることはすでに述べた。そしてχ2分布における距離とは「標準的な散らばりに対する標本データの散らばりの大きさの程度」のことである。
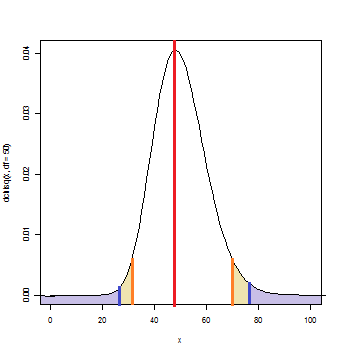
- 標本分散が基準値(=母分散)と異なる値を持つ確率(青色のついた部分の面積)をp値(=)とする。このp値が有意水準より小さいとき、「基準値≠標本分散」と言える(両側検定)。
- 標本分散が基準値より一定以上大きい値を取る確率(青色のついた部分の右側面積)をp値(>)とする。このp値が有意水準より小さいとき、「基準値>標本分散」と言える(片側検定)。
- 標本分散が基準値より一定以上小さい値を取る確率(青色のついた部分の左側面積)をp値(<)とする。このp値が有意水準より小さいとき、「基準値<標本分散」と言える(片側検定)。
data <- read.csv("http://kyoto-edu.sakura.ne.jp/weblesson/statistics/data/age.csv", fileEncoding = "utf-8")
age <- data$年齢
sigma2 <- 36.91 #母分散
N <- length(age) #サンプルサイズ
#標準誤差
SE <- sqrt(sigma2/N)
#検定統計量chisq.value
chisq.value <- sum((age - mean(age))^2)/sigma2
#p(= 基準値) 両側検定
if(var(age) > sigma2){(1 - pchisq(chisq.value, N - 1))*2}else{pchisq(chisq.value, N - 1)*2}
#p(> 基準値) 片側検定
1 - pchisq(chisq.value, N - 1)
#p(< 基準値) 片側検定
pchisq(chisq.value, N - 1)