t検定とt分布
ある集団から500人無作為抽出して得られた標本年齢データを用いる。
定年退職者が集まって様々な社会活動を行っている団体で、メンバーの高齢化が話題となった。20年前はこの団体メンバーの平均年齢は57.00歳だったが、今はそれよりも年齢が高くなっているのではないかというのだ。そこでそのメンバーから500人を無作為抽出し、年齢を調べた(設定は架空)。
- 現在のメンバーの平均年齢は何歳であると推定できるか。
- 20年前の平均年齢57.00と今回調査対象者の標本平均57.56を比較して20年前に比べて現在高齢化が進んでいると言えるだろうか。
不偏分散
母分散が分からない場合(そしてそのほうが普通だろう)、母分散の代わりにその推定値を用いるしかない。
母分散の推定値は標本分散にその標本が持つ誤差を合わせることで求められる。
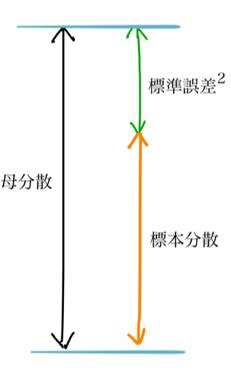
母分散 = 標準誤差^2(=母分散/N) + 標本分散(=偏差平方和/N) 両辺にNを掛ける N*母分散 = 母分散 + 偏差平方和 母分散を左辺にまとめる (N - 1)*母分散 = 偏差平方和 母分散 = 偏差平方和/(N - 1)
※標準誤差:十分な回数無作為抽出を繰り返した時の標本平均の標準偏差
ここで求められた母分散の推定値を不偏分散と呼ぶ。
そして不偏分散を求める式の分母は自由度である。
自由度
不偏分散を求める時、その式中で偏差平方和を用いているが、さらに偏差平方和を求める時に標本平均を使っている。
標本の大きさはNであるが、前提に一つ計算によって求めたものを含んでいるので、もはやこのデータにはN個の価値はない。観測値としての価値を持っているのはN-1個となる。このときこのN-1を自由度と呼ぶ。
t分布
Z検定に習って今回の検定統計量は
となる。ただしこのとき
である。
そしてこのt値の分布は正規分布に近いものとなるが、それよりも少しばらけたものとなる。
mother <- read.csv("http://kyoto-edu.sakura.ne.jp/weblesson/statistics/data/mother.csv", fileEncoding = "utf-8")
mother_age <- mother$年齢
N <-10 #サンプルサイズ10
source("http://kyoto-edu.sakura.ne.jp/weblesson/statistics/dt.test.R")
dt.test(mother_age,N)
2500回無作為抽出を行い、抽出されたデータのz値とt値をヒストグラムにする。
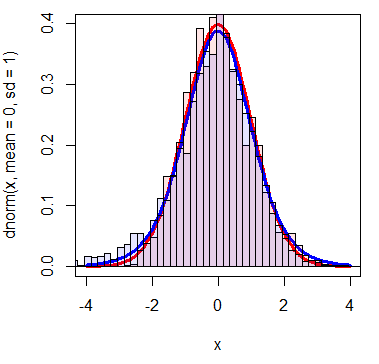
- 赤棒:z値(←平均差 / sqrt(母集団の分散/N) )
- 青棒:t値(←平均差 / sqrt(不偏分散/N) )
- 赤線:正規分布(dnorm(x,mean=0,sd=1))
- 青線:t分布(dt(x,df=N-1))
この正規分布より少しばらつきの余地を残した分布をt分布と呼ぶ※。
t分布は自由度によりその形を変え、自由度が十分大きくなれば正規分布とほぼ一致する。
curve(dnorm(x,0,1),from=-4,to=4,lwd=2,col=2) #赤 curve(dt(x,df=1),from=-4,to=4,lwd=2,add=T,col=1) #黒 curve(dt(x,df=2),from=-4,to=4,lwd=2,add=T,col=3) #緑 curve(dt(x,df=5),from=-4,to=4,lwd=2,add=T,col=4) #青 curve(dt(x,df=10),from=-4,to=4,lwd=2,add=T,col=5) #水色
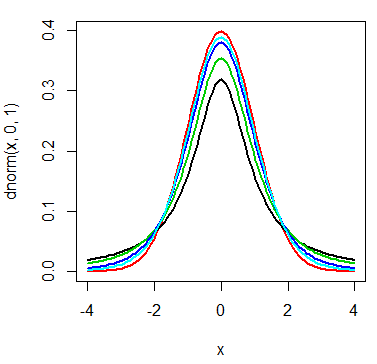
- 赤線:正規分布
- 黒線:t分布(自由度1)
- 緑線:t分布(自由度2)
- 青線:t分布(自由度5)
- 水色線:t分布(自由度10)
※ちなみにこのt分布を発見したのがペンネームStudentのW.ゴセットさん。ビール会社に勤務していた会社員だったので、ペンネームで論文発表。その意義を見出し、理論的に整備したのがR.Fisher。
t検定
t分布においては自由度が決まれば、平均差と確率の関係が一意に決まる(数学的に計算される)。
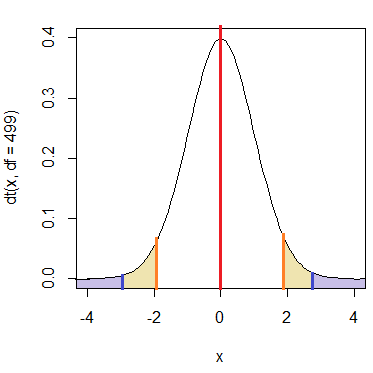
- 標本平均が基準値(=母平均)と一定以上距離を持つ確率(青色のついた部分の面積)をp値(=)とする。このp値が有意水準より小さいとき、「基準値≠標本平均」と言える(両側検定)。
- 標本平均が基準値より一定以上大きい値を取る確率(青色のついた部分の右側面積)をp値(>)とする。このp値が有意水準より小さいとき、「基準値>標本平均」と言える(片側検定)。
- 標本平均が基準値より一定以上小さい値を取る確率(青色のついた部分の左側面積)をp値(<)とする。このp値が有意水準より小さいとき、「基準値<標本平均」と言える(片側検定)。
data <- read.csv("http://kyoto-edu.sakura.ne.jp/weblesson/statistics/data/age.csv", fileEncoding = "utf-8")
age <- data$年齢
mu <- 57 #基準値
N <- length(age) #サンプルサイズ
df <- N - 1 #自由度
#標準誤差
SE <- sqrt(var(age)/N)
#検定統計量t
t.value <- (mean(age) - mu) / SE
#p(!= 基準値) 両側検定
(1 - pt(abs(t.value),df))*2
#p(> 基準値) 片側検定
1 - pt(t.value,df)
#p(< 基準値) 片側検定
pt(t.value,df)
効果量
検定統計量tはサンプルの大きさによって変化する。サンプルが大きくなればt値は大きくなり、有意という結果が出やすくなる。
サンプルの統計的な有意性としてはそれが良いのだが、一方その平均差が実際の母集団においてはどの程度の影響を持っているのかを見る時にはサンプルの大きさは無関係となる。
このサンプルサイズに影響を受けない統計量を効果量と呼ぶ。
平均の差の検定においては効果量dと効果量rが知られている。
data <- read.csv("http://kyoto-edu.sakura.ne.jp/weblesson/statistics/data/age.csv", fileEncoding = "utf-8")
age <- data$年齢
mu <- 57 #基準値
N <- length(age) #サンプルサイズ
df <- N - 1 #自由度
#標準誤差
SE <- sqrt(var(age)/N)
#検定統計量t
t.value <- (mean(age) - mu) / SE
#効果量d
(mean(age) - mu) / sd(age)
#効果量r
sqrt(t.value^2/(t.value^2 + df))
| 効果量dの絶対値 | 効果の目安 |
| 0.8 | 大 |
| 0.5 | 中 |
| 0.2 | 小 |
| 0 | なし |
| 効果量rの絶対値 | 効果の目安 |
| 0.5 | 大 |
| 0.3 | 中 |
| 0.1 | 小 |
| 0 | なし |
区間推定
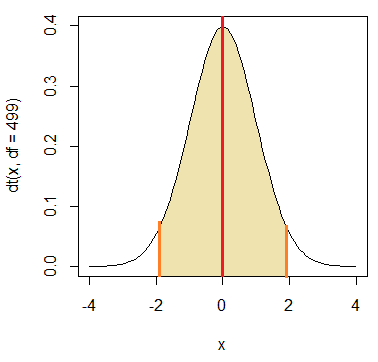
標本平均と基準値との距離が有意水準より大きい確率(橙色のついた部分の面積)内に収まる時、この平均値の範囲をもって「母平均の区間推定」とする。
標本平均が橙色のついた部分の左端に来た時、母平均(赤線)は上限となり、標本平均が右端に来た時、母平均は下限となる。
※この分布は標本平均の分布であって、母平均の分布ではない。
- 信頼上限 ← 標本平均 + 棄却値 * 標準誤差
- 信頼下限 ← 標本平均 - 棄却値 * 標準誤差
data <- read.csv("http://kyoto-edu.sakura.ne.jp/weblesson/statistics/data/age.csv", fileEncoding = "utf-8")
age <- data$年齢
N <- length(age) #サンプルサイズ
df <- N - 1
a <- 0.05 #有意水準
#標準誤差
SE <- sqrt(var(age)/N)
#棄却値
rejection <- qt(1 - a/2,df)
#信頼上限
mean(age) + rejection*SE
#信頼下限
mean(age) - rejection*SE
Rでの1サンプルのt検定
Rではt検定にはt.test()関数を用いる。
- t.test(x, mu=value, alternative="greater"/"less")
-
- x=検定変数(ベクトルデータ)
- mu=基準値
- alternative="greater"/"less" 片側検定の方向を指定する。
data <- read.csv("http://kyoto-edu.sakura.ne.jp/weblesson/statistics/data/age.csv", fileEncoding = "utf-8")
age <- data$年齢
mu <- 57 #基準値
#1サンプルのt検定(≠)
t.test(age, mu=mu)
#1サンプルのt検定(>)
t.test(age, mu=mu, alternative="greater")
#1サンプルのt検定(<)
t.test(age, mu=mu, alternative="less")