クロス集計表独立性の検定
- 本章で用いる実習用ファイル
クロス集計独立性の検定
| G | H | I | J | K | |||
|---|---|---|---|---|---|---|---|
| 1 | Conserative | unaffiliated | Democratic | 計 | |||
| 2 | Cammell | 10 | 16 | 56 | 82 | ||
| 3 | Morn | 39 | 32 | 25 | 96 | ||
| 4 | Magnol | 36 | 26 | 25 | 87 | ||
| 5 | Angerem | 31 | 25 | 35 | 91 | ||
| 6 | Juic | 16 | 33 | 23 | 72 | ||
| 7 | Beyond | 18 | 33 | 21 | 72 | ||
| 8 | 計 | 150 | 165 | 185 | 500 | ||
※ 計の部分 を周辺度数と呼ぶ。
このクロス集計表で現住所と支持政党に関連があることを読み取って良いかどうかを検証したい。
- いいたいこと:対立仮説
-
現住所と支持政党に関連がある
- 帰無仮説
-
現住所と支持政党には関連がない(相互に独立している)。関連があるように見えたとしても、それはサンプルの偏りから偶然に生じる誤差の範囲内である。
- 帰無仮説を棄却する根拠
-
完全に行(住所)と列(支持政党)が独立したクロス表と比べて、現実のクロス表(観測値)のセルごとの値はあまりにもズレが大きすぎる。こんなにズレが出るのは偶然ではあり得ない。何かしら必然的な理由(住所と支持政党に関連がある)があるのだ!
- 証明するべき事柄
-
相互に独立したクロス表の各セルの値と観測値との差の合計が偶然では起こりえないだけの大きなものであるということ
この差が生じる確率は偶然と見なせる確率(=有意水準)より小さい
- 行と列が独立した状態のクロス表を作成する
期待値(現住所*支持政党) G H I J K 19 Conserative unaffiliated Democratic 計 20 Cammell =$K2*H$8/$K$8 27.06 30.34 82 21 Morn 28.8 31.68 35.52 96 22 Magnol 26.1 28.71 32.19 87 23 Angerem 27.3 30.03 33.67 91 24 Juic 21.6 23.76 26.64 72 25 Beyond 21.6 23.76 26.64 72 26 計 150 165 185 500 Cammell府在住者である82人が、現住所に関わらない各支持政党比率(= 「計」行 の比率:Conserative:150/500, 支持なし:165/500, Democratic:185/500)で配分された状態を計算する。これを期待値と呼ぶ。
各セルの期待値 ← 列方向の周辺度数×行方向の周辺度数/合計の周辺度数
- 観測値と期待値の差(残差)を計算する
観測値 - 期待値
残差(現住所*支持政党) G H I J K 28 Conserative unaffiliated Democratic 計 29 Cammell =H2 - H20 -11.06 25.66 0 30 Morn 10.2 0.32 -10.52 0 31 Magnol 9.9 -2.71 -7.19 0 32 Angerem 3.7 -5.03 1.33 0 33 Juic -5.6 9.24 -3.64 0 34 Beyond -3.6 9.24 -5.64 0 35 計 0 0 0 0 - 残差を標準化する
残差 / SQRT(期待値)
クロス表各セルの期待値というのは各セルの規模を表している(サンプルサイズに依存する)。サンプルサイズが小さければ期待値も小さくなり、残差も小さくなる。この規模感を一定のものにするのが「標準化」である。
標準化残差(現住所*支持政党) G H I J K 37 Conserative unaffiliated Democratic 計 38 Cammell =H29/SQRT(H20) -2.13 4.66 0 39 Morn 1.90 0.06 -1.77 0 40 Magnol 1.94 -0.51 -1.27 0 41 Angerem 0.71 -0.92 0.23 0 42 Juic -1.20 1.90 -0.71 0 43 Beyond -0.77 1.90 -1.09 0 44 計 0 0 0 0 - 標準化残差を2乗する
標準化残差はセルごとに正負混ざる。表全体の観測値と期待値のズレの大きさを計算するために標準化残差を2乗する(分散のときに偏差を2乗したのと同じ意味)。
標準化残差^2(現住所*支持政党) G H I J K 46 Conserative unaffiliated Democratic 計 47 Cammell =H38^2 4.52 21.70 0 48 Morn 3.61 0.00 3.12 0 49 Magnol 3.76 -0.51 1.61 0 50 Angerem 0.50 0.26 0.05 0 51 Juic 1.45 3.59 0.50 0 52 Beyond 0.60 3.59 1.19 0 53 計 0 0 0 0 - 各セルの標準化残差の平方和を計算する
表全体の観測値と期待値のズレの大きさを数値化する。これが検定統計量χ2値。χ2が大きくなればなるほど、それが生じる確率は下がる。
このχ2値はχ2分布という確率分布(大きさとそれが生じる確率とを対応させたもの)を取る。χ2分布は自由度によって形が変わる(t分布と同様)。
G H I J K 55 χ2値 自由度 p値 V 56 Peason =SUM(H47:J52) - 自由度の計算をする
検定統計量χ2値はサンプルサイズではなく、クロス表のセルの個数ベースで計算されている。というわけで(周辺度数を除く)セルの数は6*3個。しかし残差計算のときに各行・各列の合計値を用いているので、自由度はその分、差し引かなければならない。
1 2 3 4 5 17 1 2 3 4 5 18 13 3 5 7 9 11 13 48 周辺度数が既知のとき、青い部分が決まれば、残りのセルが確定する。つまり自由度は青い部分の個数、(行数-1)*(列数-1)。
G H I J K 55 χ2値 自由度 p値 V 56 Peason 59.56 =(COUNTA(G47:G52)-1)*(COUNTA(H47:J47)-1) - p値を求める
χ2値はχ2分布いう確率分布(大きさとその出現確率を対応させる)を取る。χ2分布は自由度によって形が変わる。
自由度が10のχ2分布 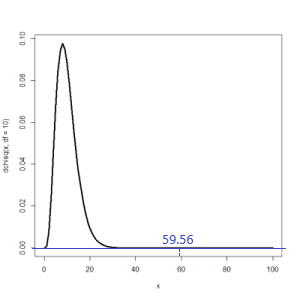
この検定は「期待値と観測値が異なっている」ことを示す両側検定である。ただし観測値 - 期待値を2乗しているので、棄却値はグラフの右側にしか出ない。したがって数式上ではz検定・t検定・F検定の片側検定と同等になる(なおこのクロス表では観測値 - 期待値の符号が確定しないので(セルによって異なる)、片側検定は存在しない)。
G H I J K 55 χ2値 自由度 p値 V 56 Peason 59.56 10 =1-CHISQ.DIST(H56,I56,TRUE) - 効果量CramerのV値
χ2値はサンプルサイズによって変化する。その影響を排除し、クロス表の大きさ(自由度)の影響を補正したものが効果量 CramerのV値である。
SQRT(χ2/(サンプルサイズ*(行数、列数の少ない方-1)))
G H I J K 55 χ2値 自由度 p値 V 56 Peason 59.56 10 0.00 =SQRT(H56/(K8*(MIN(COUNTA(G47#),COUNTA(H46:J46))-1))) CramerのV値 効果量V 効果の目安 0.5 大 0.3 中 0.1 小 0 なし
自由度1のクロス表
クロス表の自由度が1の時、すなわち2*2のクロス表の時は別に考えることがある。
性自認×内閣支持のクロス表を例にする。
| M | N | O | P | |||
|---|---|---|---|---|---|---|
| 1 | Yes | No | 計 | |||
| 2 | male | 124 | 120 | 244 | ||
| 3 | female | 107 | 149 | 256 | 4 | 計 | 231 | 269 | 500 |
自由度が1であるということは一つのセルで観測値 - 期待値の符号が決まれば、それですべてのセルの符号も確定する。つまりこのときには片側検定に意味が出る。符号は1/2の確率で定まるので、両側検定のp値を2で割った値となる。
| M | N | O | P | Q | R | S | |||
|---|---|---|---|---|---|---|---|---|---|
| 55 | χ2値 | 自由度 | p(≠) | p(>) | p(<) | V | |||
| 56 | Peason | 4.09 | 1 | 0.04 | =P56/2 | =1-P56/2 | 0.09 | ||
Yates補正
χ2分布はこれまでの確率分布と同様連続変数(量的な値=比例・間隔尺度)を対象としている。しかしクロス表では観測値は整数しか取らない離散変数である。このためクロス表から求めたχ2値に対してχ2分布は近似値を示すに過ぎない。このため今まで求めてきたクロス表独立性検定のp値は漸近有意確率と呼ぶ。漸近有意確率はクロス表の自由度が十分に大きければ一定の信頼性があるが、自由度が1のときにはその歪みが大きいことが知られている。ということでそれを補正する手段としてYates補正(連続修正)がある。
標準化残差を計算するときに補正をかける。
(ABS(残差) - 0.5) / SQRT(期待値)
| R | S | T | U | |||
|---|---|---|---|---|---|---|
| 37 | Yes | No | 計 | |||
| 38 | male | =(ABS(N29)-0.5)/SQRT(N20) | 0.94 | 0 | ||
| 39 | female | 0.99 | 0.92 | 0 | 40 | 計 | 0 | 0 | 0 |
これを元にχ2検定を行う。
| M | N | O | P | Q | R | S | |||
|---|---|---|---|---|---|---|---|---|---|
| 55 | χ2値 | 自由度 | p(≠) | p(>) | p(<) | V | |||
| 56 | Peason | 4.09 | 1 | 0.04 | 0.02 | 0.98 | 0.09 | ||
| 57 | Yates | 3.74 | 1 | 0.05 | 0.03 | 0.97 | |||
Peasonでは有意だったが、Yatesでは帰無仮説は棄却できない。
残差分析
χ2分布を用いた独立性の検定はクロス集計全体で行項目と列項目の関係を読み取ることが出来るかどうかを検証するためのものである。個別セルに対する読み取り(Cammell府在住者はDemocratic等を支持する傾向があるなど)の有意性を検証したわけではない。そこでセルごとの傾向とその有意性を改めて検証する。この分析を残差分析と呼ぶ(分散分析と多重比較検定の関係に似ている)。
| G | H | I | J | K | |||
|---|---|---|---|---|---|---|---|
| 37 | Conserative | unaffiliated | Democratic | 計 | |||
| 38 | Cammell | -2.94 | -2.13 | 4.66 | 0 | ||
| 39 | Morn | 1.90 | 0.06 | -1.77 | 0 | ||
| 40 | Magnol | 1.94 | -0.51 | -1.27 | 0 | ||
| 41 | Angerem | 0.71 | -0.92 | 0.23 | 0 | ||
| 42 | Juic | -1.20 | 1.90 | -0.71 | 0 | ||
| 43 | Beyond | -0.77 | 1.90 | -1.09 | 0 | ||
| 44 | 計 | 0 | 0 | 0 | 0 | ||
標準化残差の符号からセルごとのズレの方向(Cammell在住者であることはConserative党の支持に対して負の効果を持つ)を読み取る。こうしたセルごとの解釈が統計的有意性を持つかどうかが問題となる。
この標準化残差は期待値に対する観測値のズレの大きさを標準化したものである。それに対して期待値自体の持つズレの大きさを残差分散と呼ぶ。残差分散は期待値の「裏」の計算をする。
| G | H | I | J | K | |||
|---|---|---|---|---|---|---|---|
| 1 | Conserative | unaffiliated | Democratic | 計 | |||
| 2 | Cammell | 10 | 16 | 56 | 82 | ||
| 3 | Morn | 39 | 32 | 25 | 96 | ||
| 4 | Magnol | 36 | 26 | 25 | 87 | ||
| 5 | Angerem | 31 | 25 | 35 | 91 | ||
| 6 | Juic | 16 | 33 | 23 | 72 | ||
| 7 | Beyond | 18 | 33 | 21 | 72 | ||
| 8 | 計 | 150 | 165 | 185 | 500 | ||
| G | H | I | J | |||
|---|---|---|---|---|---|---|
| 57 | Conserative | unaffiliated | Democratic | |||
| 58 | Cammell | =(1-$K2/$K$8)*(1-H$8/$K$8) | 0.56 | 0.53 | ||
| 59 | Morn | 0.57 | 0.54 | 0.51 | ||
| 60 | Magnol | 0.58 | 0.55 | 0.52 | ||
| 61 | Angerem | 0.57 | 0.55 | 0.52 | ||
| 62 | Juic | 0.60 | 0.57 | 0.54 | ||
| 63 | Beyond | 0.60 | 0.57 | 0.54 | ||
この残差分散の平方根を取ったものが今回の標準誤差となる。
| G | H | I | J | |||
|---|---|---|---|---|---|---|
| 66 | Conserative | unaffiliated | Democratic | |||
| 67 | Cammell | =SQRT(H58) | 0.75 | 0.73 | ||
| 68 | Morn | 0.75 | 0.74 | 0.71 | ||
| 69 | Magnol | 0.76 | 0.74 | 0.72 | ||
| 70 | Angerem | 0.76 | 0.74 | 0.72 | ||
| 71 | Juic | 0.77 | 0.76 | 0.73 | ||
| 72 | Beyond | 0.77 | 0.76 | 0.73 | ||
標準化残差を標準誤差で調整するとz検定の検定統計量z値となる。このときのz値を調整済み標準化残差と呼ぶ。
| G | H | I | J | |||
|---|---|---|---|---|---|---|
| 74 | Conserative | unaffiliated | Democratic | |||
| 75 | Cammell | =H38/H67 | -2.84 | 6.42 | ||
| 76 | Morn | 2.53 | 0.08 | -2.47 | ||
| 77 | Magnol | 2.53 | -0.68 | -1.76 | ||
| 78 | Angerem | 0.94 | -1.24 | 0.32 | ||
| 79 | Juic | -1.56 | 2.50 | -0.96 | ||
| 80 | Beyond | -1.00 | 2.50 | -1.49 | ||
この調整済み標準化残差(z値)は標準正規分布を取るので、そこからp値を求める。
| G | H | I | J | |||
|---|---|---|---|---|---|---|
| 82 | Conserative | unaffiliated | Democratic | |||
| 83 | Cammell | =(1-NORM.S.DIST(ABS(H75),TRUE))*2 | 0.45% | 0.00% | ||
| 84 | Morn | 1.15% | 93.84% | 1.34% | ||
| 85 | Magnol | 1.08% | 49.66% | 7.90% | ||
| 86 | Angerem | 34.94% | 21.50% | 74.95% | ||
| 87 | Juic | 11.96% | 1.23% | 33.69% | ||
| 88 | Beyond | 31.70% | 1.23% | 13.67% | ||
p値が5%未満のセルが有意である。有意なセルに対して標準化残差の符号を読み取ることが出来る。
- Camell在住者は保守党支持と支持なし層が少なく、民主党支持が多い
- Morn在住者は保守党支持が多く、民主党支持が少ない
- Magnol在住者は保守党支持が少ない
- Juic在住者は支持なし層が多い
- Beyond在住者は支持なし層が多い
結果
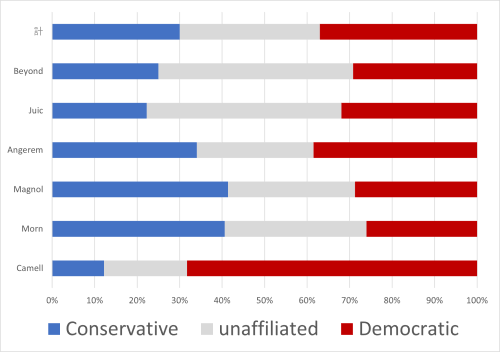
居住地域によって支持政党は異なっている(χ2(10)=59.56, p<.05, V=0.24)。Cammell府在住者は民主党Democratic支持傾向が強く(z=6.42, p<.05)、Morn府(z=2.53, p<.05))・Magnol府(z=2.55, p<.05)在住者は保守党支持傾向が強い。