Rによるクロス集計と独立性の検定1
μ国で有権者を対象に政治意識調査を行った。調査は無作為抽出で対象者を選び、500人から回答を得られた。
- 問1 あなたの性自認(Gender)は何ですか。
-
- 男性(male)
- 女性(female)
- 問2 あなたの住所登録がなされている府(Prefecture)はどこですか。
-
- Morn
- Angerm
- Juic
- Magnol
- Camell
- Beyond
- 問3 あなたの支持政党(Party)は何党ですか。
-
- 保守党(Conservative)
- 民主党(Democratic)
- 特になし(unaffiliated)
- 問4 あなたは現内閣を支持(CabinetSupport)しますか。
-
- 支持する(Yes)
- 支持しない(No)
この調査から得られたデータより、現住所(Prefecture)と支持政党(Party)との関連に付いて得られる知見を述べよ。
スクリプト
data <- read.csv("http://kyoto-edu.sakura.ne.jp/weblesson/statistics/data/chiSq.Test.Independence.csv")
summary(data)
#クロス集計
source("http://kyoto-edu.sakura.ne.jp/weblesson/statistics/socialStatisticsBasic.R")
crossTable <- crosstab(Prefectures, Party, data)
#χ2検定他
result <- summary(crossTable)
#結果出力
result
#帯グラフ
barplot(t(result$row.ratio), horiz=T, legend=colnames(result$row.ratio))
#ファイルへの書き出し
write.output(result,"output.crosstable.csv")
crosstab関数(socialStatisticsBasic.Rで読み込まれる自作関数)
- crosstab(row,column,data)
-
- row=行データとなる項目名
- column=列データとなる項目名
- data=モデル中の変数を含むデータフレーム(row, columnがおのおの実体を持つ時は省略可)
出力結果
クロス集計表
$crossTable
Conservative Democratic unaffiliated
Angerem 31 35 25
Beyond 18 21 33
Camell 10 56 16
Juic 16 23 33
Magnol 36 25 26
Morn 39 25 32
$row.ratio
Conservative Democratic unaffiliated
Angerem 0.3406593 0.3846154 0.2747253
Beyond 0.2500000 0.2916667 0.4583333
Camell 0.1219512 0.6829268 0.1951220
Juic 0.2222222 0.3194444 0.4583333
Magnol 0.4137931 0.2873563 0.2988506
Morn 0.4062500 0.2604167 0.3333333
$column.ratio
Conservative Democratic unaffiliated
Angerem 0.20666667 0.18918919 0.15151515
Beyond 0.12000000 0.11351351 0.20000000
Camell 0.06666667 0.30270270 0.09696970
Juic 0.10666667 0.12432432 0.20000000
Magnol 0.24000000 0.13513514 0.15757576
Morn 0.26000000 0.13513514 0.19393939
この調査で見たいのは現住所(居住地域)で政治的意識がどのような違いが出るか、である。このように属性的なものと意識・行動との関連を見るときにクロス集計表は用いられる。しかし属性によるカテゴリーのサンプルサイズが異なれば、その意識・行動の違いを観測値ベースで比較してもあまり意味がない。
| 投票に行く | 行かない | 計 | |
|---|---|---|---|
| 20以上 | 25 | 25 | 50 |
| 20未満 | 30 | 70 | 100 |
| 計 | 55 | 95 | 150 |
このようなクロス表が得られたとして、20未満の学生は20以上の学生より投票に行く傾向がある、という解釈は端的に間違っている。投票に行くとしているのが、20以上の学生は50%に対して、20未満の学生は30%に過ぎない。つまり比率で比較しなければならない。
というわけで比率計算を行う。
比率計算(部分/全体)は分母となる基準値をどこに置くかによって3種類ある。一般的にクロス集計表で欲しい比率は属性ごとの比率なので、属性を行側に置けば「行方向の比率」を用いる。
| 投票に行く | 行かない | 計 | |
|---|---|---|---|
| 20以上 | 50.00% | 50.00% | 100.00% |
| 20未満 | 30.00% | 70.00% | 100.00% |
| 計 | 36.67% | 63.33% | 100.00% |
| 投票に行く | 行かない | 計 | |
|---|---|---|---|
| 20以上 | 45.45% | 26.32% | 33.33% |
| 20未満 | 54.55% | 73.68% | 66.67% |
| 計 | 100.00% | 100.00% | 100.00% |
| 投票に行く | 行かない | 計 | |
|---|---|---|---|
| 20以上 | 16.67% | 16.67% | 33.33% |
| 20未満 | 20.00% | 46.67% | 66.67% |
| 計 | 36.67% | 63.33% | 100.00% |
今回は居住地域別クラスターで支持政党がどう違うか、を知りたいので、行方向($row.ratio)の比率を見る。
χ2検定
$chisq.test
chi sq df P
Peason 59.56225 10 4.385443e-09
Fisher NA NA 4.997501e-04
- $chisq.test
-
- Peason→「Pearsonのカイ2乗:漸近有意確率(両側)」
- Yates→「連続修正:漸近有意確率(両側)」(※自由度1の時のみ出力)
- Fisher→「Fhisherの直接法:正確な有意確率(両側)」(※計算量によっては出力されない)
この検定は「期待値と観測値が異なっている」ことを示す両側検定である。ただし観測値 - 期待値を2乗しているので、棄却値はグラフの右側にしか出ない。したがって数式上ではz検定・t検定・F検定の片側検定と同等になる(なおこのクロス表では観測値 - 期待値の符号が確定しないので(セルによって異なる)、片側検定は存在しない)。
一般的にはPeasonを参照すれば良い。
残差分析
χ2分布を用いた独立性の検定はクロス集計全体で行項目と列項目の関係を読み取ることが出来るかどうかを検証するためのものである。個別セルに対する読み取り(Cammell府在住者はDemocratic等を支持する傾向があるなど)の有意性を検証したわけではない。そこでセルごとの傾向とその有意性を改めて検証する。この分析を残差分析と呼ぶ(分散分析と多重比較検定の関係に似ている)。
$residualAnalysis
Conservative Democratic unaffiliated
Angerem 0.9358252 0.3192884 -1.2398703
Beyond -1.0006673 -1.4880065 2.5030785
Camell -3.8479830 6.4191193 -2.8408656
Juic -1.5565936 -0.9603446 2.5030785
Magnol 2.5484487 -1.7567425 -0.6798690
Morn 2.5272559 -2.4740206 0.0772706
ここで出力されているのは調整済み標準化残差である。この符号からセルごとのズレの方向(Cammell在住者であることはConserative党の支持に対して負の効果を持つ)を読み取る。こうしたセルごとの解釈が統計的有意性を持つかどうかが問題となる。
$res.p.value
Conservative Democratic unaffiliated
Angerem 0.3494 0.7495 0.2150
Beyond 0.3170 0.1367 0.0123
Camell 0.0001 0.0000 0.0045
Juic 0.1196 0.3369 0.0123
Magnol 0.0108 0.0790 0.4966
Morn 0.0115 0.0134 0.9384
p値が5%未満の値が有意である。有意なセルに対して標準化残差の符号を読み取ることが出来る。
- Camell在住者は保守党支持と支持なし層が少なく、民主党支持が多い
- Morn在住者は保守党支持が多く、民主党支持が少ない
- Magnol在住者は保守党支持が少ない
- Juic在住者は支持なし層が多い
- Beyond在住者は支持なし層が多い
効果量Cramer's V
$Cramer
[,1]
Cramer's V 0.2440538
- Cramer's V
-
Cramer's Vの目安 効果量V 効果の目安 0.5 大 0.3 中 0.1 小 0 なし
考察例
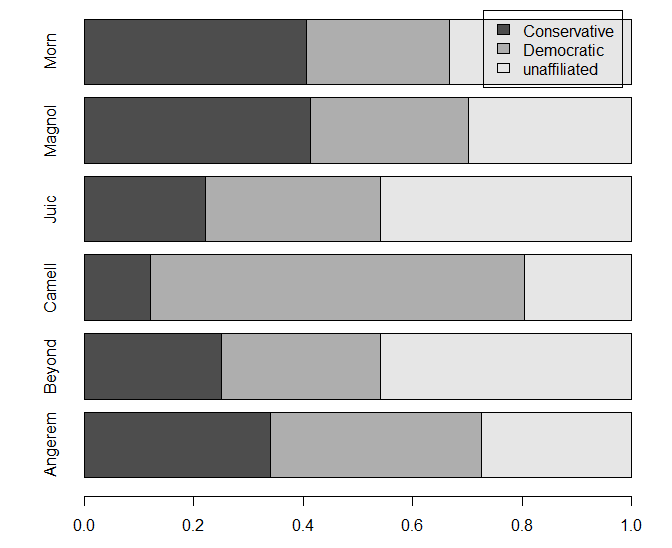
居住地域によって支持政党は異なっている(χ2(10)=59.56, p<.05, V=0.24)。Cammell府在住者は民主党Democratic支持傾向が強く(z=6.42, p<.05)、Morn府(z=2.53, p<.05))・Magnol府(z=2.55, p<.05)在住者は保守党支持傾向が強い。
自由度1のクロス表
クロス表の自由度が1の時、すなわち2*2のクロス表の時は別に考えることがある。
スクリプト
#クロス集計 crossTable <- crosstab(Gender, CabinetSupport, data) #χ2検定他 result <- summary(crossTable) #結果出力 result
クロス表
性自認×内閣支持のクロス表を考える。このクロス表は自由度1となる。
$crossTable
No Yes
female 149 107
male 120 124
Yates補正
χ2分布はこれまでの確率分布と同様連続変数(量的な値=比例・間隔尺度)を対象としている。しかしクロス表では観測値は整数しか取らない離散変数である。このためクロス表から求めたχ2値に対してχ2分布は近似値を示すに過ぎない。このため今まで求めてきたクロス表独立性検定のp値は漸近有意確率と呼ぶ。漸近有意確率はクロス表の自由度が十分に大きければ一定の信頼性があるが、自由度が1のときにはその歪みが大きいことが知られている。ということでそれを補正する手段としてYates補正(連続修正)がある。
$chisq.test
chi sq df P
Peason 4.091833 1 0.04309088
Yates 3.736876 1 0.05322388
Fisher NA NA 0.04845768
Peasonでは有意だったが、Yatesでは帰無仮説は棄却できない。