平均値に関する論証2:基準値との比較:z検定
量的調査データの「解釈」(再掲)
量的調査データにおいて、解釈は「記述・推測的解釈」と「批評的解釈」の二段階に分けて行う。
主張
←批評的解釈
統計的知見
←記述・推測的解釈
量的調査
データ
量的調査
データ
文脈(サンプル)
文脈(母集団)
- 記述・推測的解釈…統計に基づく「解釈」(脱文脈的)
- 批評的解釈…外部理論などに基づく「解釈」(文脈依存的)
例題:基準値との比較
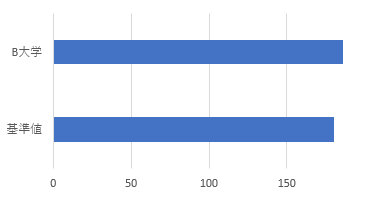
μ国では大学生のスマートフォンの利用が勉学に悪影響を及ぼしているのではないかと社会問題化している。B大学でも学生のスマートフォン利用時間が増大しているのではないかと懸念が出て、独自に調査することになった。教育省が全国の大学生について1年前に調査した時には平均利用時間180分(分散5,500)であった。今回B大学は全学生の中から500人を無作為抽出を行い、スマートフォン利用時間について調べたところ、下記データが得られた。
このデータより、B大学の学生のスマートフォン利用時間は1年前の全国大学平均と比べて利用時間が長いと言えるだろうか?
結果出力例
| 基準値 | B大学 | |
|---|---|---|
| 平均値 | 180 | 185.83 |
問題1
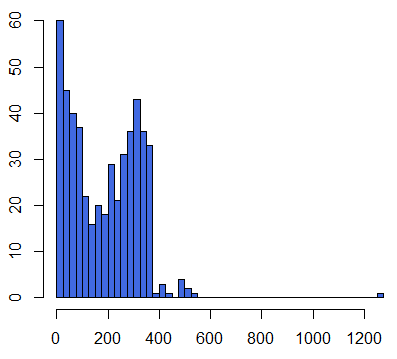
図表2は平均値と分布 図表1改と同等の結果に見える。ならば同等に結論づけてよいか。
A大学とB大学のスマートフォン利用時間データにおいて、決定的な違いはどこにあるか。
作業
- B大学のデータについてヒストグラムを作成せよ。
- A大学のヒストグラム(図1-2)との違いを簡潔に説明せよ。
- A大学の分散とB大学の不偏分散を各々求めよ。
Rスクリプト例
#分析用スクリプトの読み込み(初回のみでよい)
source("http://kyoto-edu.sakura.ne.jp/weblesson/statistics/socialStatisticsBasic.R", encoding="UTF-8")
#データの読み込み
dataA <- read.csv("http://kyoto-edu.sakura.ne.jp/weblesson/statistics/data/smartphone00-A.csv", fileEncoding = "utf-8")
dataB <- read.csv("http://kyoto-edu.sakura.ne.jp/weblesson/statistics/data/smartphone00-B.csv", fileEncoding = "utf-8")
#読み込みデータ概要確認
summary(dataA)
summary(dataB)
#変数指定
time.A <- dataA$time
time.B <- dataB$time
#利用時間のヒストグラムと度数分布表
start <- 0 #区切りの開始位置
width <- 25 #区切りの幅
#記述統計
output.descriptive_00_A <- descriptive(time.A,start,width)
output.descriptive_00_B <- descriptive(time.B,start,width)
#ファイルへの書き出し
write.output(output.descriptive_00_A,"output.descriptive_00_A.csv")
write.output(output.descriptive_00_B,"output.descriptive_00_B.csv")
結果出力例
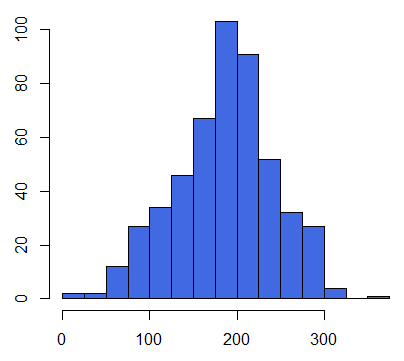
B大学の分布は平均付近を中心とした山型となっており、A大学のデータと異なり、平均値に意味を読み取ることが出来る。
- A大学データの不偏分散:18507.72
- B大学データの不偏分散: 3223.81
問題2
B大学のデータについて、基準値(180分)を上回っていると言えるか。
- Z検定を行い、Z値とp値を求めよ
- 片側検定か両側検定かを判断し、結果を読み取れ(「記述・推測的解釈」)。
- 「有意」と判断(信頼度95%)できた場合は検定結果から読み取れる「主張」を簡潔に記述せよ(「批評的解釈」)。
- 記述・推測的解釈…統計から得られた知見を客観的に記述する。
- 批評的解釈…統計的知見を「根拠」として、文脈に合わせて自由に議論を進める。
主張テンプレート
B大学学生のスマートフォン平均利用時間が1年前の全国平均(180.00)と差があるかどうかを平均の差の検定を用いて検証した。今回の調査で得られた標本の平均利用時間は○である。Z検定(片側/両側)より5%の危険度で有意であると確認できた(Z=●, p<.05)。
この結果よりB大学学生のスマートフォン平均利用時間は1年前の全国平均より■■。
…(以下、批評的解釈に基づく主張)
Rスクリプト例
#分析用スクリプトの読み込み(初回のみでよい)
source("http://kyoto-edu.sakura.ne.jp/weblesson/statistics/socialStatisticsBasic.R", encoding="UTF-8")
#データの読み込み(前回と同じデータを用いるので省略可)
dataB <- read.csv("http://kyoto-edu.sakura.ne.jp/weblesson/statistics/data/smartphone00-B.csv")
#変数指定(前回と同じ変数を用いるので省略可)
time.B <- dataB$time
#基準値設定
testVal <- 180
sigma2 <- 5500
#z検定
output.z.test_00_B <- z.test(time.B,testVal,sigma2)
#結果出力
output.z.test_00_B
#ファイルへの書き出し
write.output(output.z.test_00_B,"output.z.test_00_B.csv")
出力結果
$statistics
summary
N 500.00000
df 499.00000
mean 185.83400
u2 3223.81407
u 56.77864
Missing Value 0.00000
$z_test
z-test
SE 3.31662479
Z 1.75901718
rejection 1.95996398
p(!=) 0.07857459
p(>) 0.03928729
p(<) 0.96071271
Upper 192.33446514
Lower 179.33353486
主張例
B大学学生のスマートフォン平均利用時間が1年前の全国平均(180.00)より長いかどうかを平均の差の検定を用いて検証した。今回の調査で得られた標本の平均利用時間は185.83である。Z検定(片側)より5%の危険度で有意であると確認できた(Z=1.76, p<.05)。
この結果よりB大学学生のスマートフォン平均利用時間は1年前の全国平均より長い。
全国水準でなされた学生のスマートフォン利用時間が長すぎるという懸念に関して、B大学学生も当てはまるものと考えられる。
課題
μ国の全大学生のスマートフォン平均利用時間は180分(分散5,500)である。B大学は全学生の中から500人を無作為抽出を行い、スマートフォン利用時間について調べたところ、下記結果が得られた。
| 基準値 | B大学 | |
|---|---|---|
| 平均値 | 180 | 185.83 |
この結果より、B大学の学生のスマートフォン利用時間は1年前の全大学生平均と比べて利用時間は長いと言えるだろうか?
主張例
B大学学生のスマートフォン平均利用時間が1年前の全国平均(180.00)と差があるかどうかを平均の差の検定を用いて検証した。今回の調査で得られた標本の平均利用時間は185.83である。Z検定(両側)より5%の危険度で有意性が観られなかった(Z=1.76, p=.08)。