平均値に関する論証1:平均値と分散
量的調査データの「解釈」
量的調査データにおいて、解釈は「記述・推測的解釈」と「批評的解釈」の二段階に分けて行う。
主張
←批評的解釈
統計的知見
←記述・推測的解釈
量的調査
データ
量的調査
データ
文脈(サンプル)
文脈(母集団)
- 記述・推測的解釈…統計に基づく「解釈」(脱文脈的)
- 批評的解釈…外部理論などに基づく「解釈」(文脈依存的)
例題1:平均値と分布
μ国では大学生のスマートフォンの利用が勉学に悪影響を及ぼしているのではないかと社会問題化している。A大学でも学生のスマートフォン利用時間が増大しているのではないかと懸念が出て、独自に調査することになった。教育省が全国の大学生について1年前に調査した時には平均利用時間180分(分散5,500)であった。今回A大学は全学生の中から500人を無作為抽出を行い、スマートフォン利用時間について調べたところ、下記データが得られた。
このデータより、A大学の学生のスマートフォン利用時間は1年前の全国大学平均と比べて利用時間が長いと言えるだろうか?
解答例

図1-1よりA大学学生は1年前の学生の全国平均と比較して、スマートフォン利用時間は長いことが分かる。
問題1
この解釈は妥当だろうか?
解答例グラフ修正
| 基準値 | A大学 | |
|---|---|---|
| 平均値 | 180 | 185.76 |
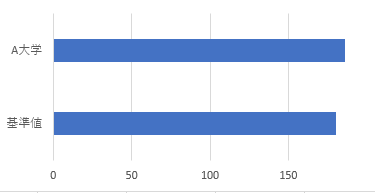
図表1-1改よりA大学学生のスマートフォン利用時間の平均は1年前の学生の全国平均と比較して、5.76分長い。
問題2 この先の分析方針
この6分弱の差から何を読み取るべきだろうか。
- 表およびグラフから差がないと読み取る
- 表およびグラフから特筆するほどの差があるとも読み取れないので、スルーする(このデータから議論を進めるのを断念する)
- 差があると言える可能性があるので、さらに分析を進める
あなたならどの方針で進めるか?
Rスクリプト例
#分析用スクリプトの読み込み
source("http://kyoto-edu.sakura.ne.jp/weblesson/statistics/socialStatisticsBasic.R", encoding="UTF-8")
#データの読み込み
dataA <- read.csv("http://kyoto-edu.sakura.ne.jp/weblesson/statistics/data/smartphone00-A.csv", fileEncoding = "utf-8")
#読み込みデータ概要確認
summary(dataA)
#変数指定
x <- dataA$time
#利用時間のヒストグラムと度数分布表
start <- 0 #区切りの開始位置
width <- 25 #区切りの幅
#記述統計
output.descriptive_00_A <- descriptive(x,start,width)
#ファイルへの書き出し
write.output(output.descriptive_00_A,"output.descriptive_00_A.csv")
解答例
- 量的調査系の理論では不可。「差がない」ことは統計的には論証できない。
- データから主張を引き出すことを断念する「権利」はいつでもある。
- 分析を続けるのであれば、まずは分布をグラフにする。
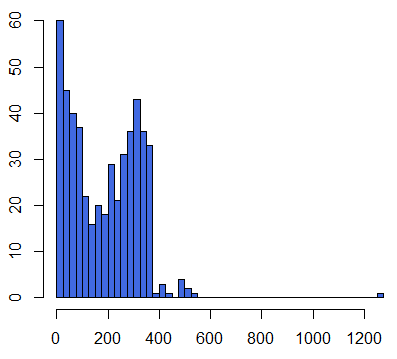
分布が山型ではないので平均値に関する信頼性は高くない。最頻値など他の代表値で議論を進めることを検討する。
ただし今回は比較対象が平均値しかないので、分析を続けるのは困難。