平均値と分布
- 本章で用いる実習用ファイル
μ国では大学生のスマートフォンの利用が勉学に悪影響を及ぼしているのではないかと社会問題化している。A大学でも学生のスマートフォン利用時間が増大しているのではないかと懸念が出て、独自に調査することになった。教育省が全国の大学生について1年前に調査した時には平均利用時間180分(分散5,500)であった。今回A大学は全学生の中から500人を無作為抽出を行い、スマートフォン利用時間について調べたところ、下記データが得られた。
| A | B | C | D | E | F | G | H | I | |
|---|---|---|---|---|---|---|---|---|---|
| 1 | No | gender | faculty | time | 平均値 | 分散 | |||
| 2 | 1 | female | science | 150 | 基準値 | 180.00 | 5500.00 | ||
| 3 | 2 | female | law | 266 | A大学 | ||||
| 4 | 3 | male | science | 293 | |||||
| μ国A大学スマートフォン利用時間調査データ | |||||||||
- time(比例尺度)
- D2:D501
このデータより、A大学の学生のスマートフォン利用時間は1年前の全国大学平均と比べて利用時間が長いと言えるだろうか?
平均値の算出とグラフ作成
- A大学の平均値を求める。
F G 1 平均 2 基準値 180.00 3 A大学 =AVERAGE(time) - F2:G3のデータで棒グラフを作成する。
F G 1 平均 2 基準値 180.00 3 A大学 185.764
解答例

図1-1よりA大学学生は1年前の学生の全国平均と比較して、スマートフォン利用時間は長いことが分かる。
問題1:グラフ評価
この解釈は妥当だろうか?
解答例グラフ修正
| 平均 | |
|---|---|
| 基準値 | 180.00 |
| A大学 | 185.7 |
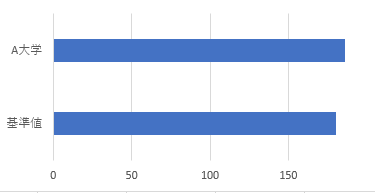
図表1-1改よりA大学学生のスマートフォン利用時間の平均は1年前の学生の全国平均と比較して、5.76分長い。
問題2:次の方針
この6分弱の差から何を読み取るべきだろうか。
- 表およびグラフから差がないと読み取る
- 表およびグラフから特筆するほどの差があるとも読み取れないので、スルーする(このデータから議論を進めるのを断念する)
- 差があると言える可能性があるので、さらに分析を進める
あなたならどの方針で進めるか?
解答例
度数分布表とヒストグラム
- 基本統計量を求める
F G 5 サンプルサイズ =COUNT(time) 6 平均値 =AVERAGE(time) 7 中央値 =MEDIAN(time) 8 最頻値 9 最大値 =MAX(time) 10 最小値 =MIN(time) 11 範囲 =G9 - G10 12 分散 =VAR.S(time) 13 標準偏差 =STDEV.S(time) - 度数分布表を作成する
- ビンの設定
サンプルサイズが「500」、最小値が「0」、最大値が「1260」、範囲が「1260」から、最小「0」区切り幅「100」のビンを設定する。
- 度数分布表を作成
I J 5 ビン 人数 6 0 =COUNT(IF((time>=I6)*(time<I7),1)) 7 100 76 8 200 117 9 300 113 10 400 8 11 500 3 12 600 0 18 1200 1 - 区切り幅の見直し
最大値が外れ値となっており、実質的な階層は6層と少なく、階層あたりの人数が多い。もっと区切りを細かく設定した方が良い。
最小「0」区切り幅「50」でビンを設定し直す。
- 度数分布表作り直し
I J 5 ビン 人数 6 0 105 7 50 77 8 100 38 9 150 38 10 200 50 11 250 67 12 300 79 31 1250 1 - ヒストグラムを作成する
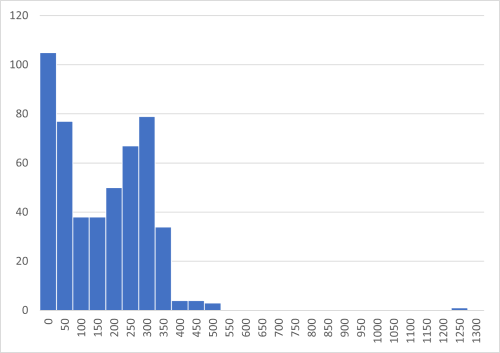
図1-2 A大学スマートフォン利用時間ヒストグラム
- ビンの設定
分布が山型ではないので平均値に関する信頼性は高くない。最頻値(25)など他の代表値で議論を進めることを検討する。
ただし今回は比較対象が平均値しかないので、分析を続けるのは困難。