Rによる独立した2グループ間での平均値に対する検定
所属メンバーが異なっている2集団の平均の比較を行いたいときには「独立したサンプルのt検定」を行う。
μ国B大学スマートフォン利用時間調査データ(架空データ)を用いる。
B大学の学生の中から無作為抽出を行い、1日あたりのスマートフォン利用時間について500人から回答を得た。このデータからスマートフォン利用時間に関するジェンダー差を知りたい。
下記データより、B大学の学生のスマートフォン利用時間について、男子学生と女子学生の違いについてデータから得られる知見を述べよ。
t検定には等分散性を前提としたStudentのt検定と等分散を前提としないより頑健(ロバスト)なWelch修正が知られている。等分散性の検定を行ってからどちらの検定法を用いるか判断するのは「検定の繰り返し」であり、望ましくない。最初から頑健性の高いとされているWelch法を用いる。Rのt.test関数ではデフォルトでこのWelch法が用いられるようになっている(Student法を用いるためにはオプションvar.equal=Tを設定する)。
本実習ではRの標準機能であるt.test関数ではなく、効果量も含め、必要な値を全部出力するスクリプト(独自関数)を利用する。
Rスクリプト
#データの読み込み
data <- read.csv("http://kyoto-edu.sakura.ne.jp/weblesson/statistics/data/smartphone00-B.csv")
#本例ではウェブ上に公開されているcsvデータをダイレクトに読み込んでいる
#ローカルにあるcsvファイルを読み込むときには
# data <- read.csv(file.choose())
#読み込んだデータの概略を確認する
summary(data)
#データから変数を指定する
x <- data$time
group <- factor(data$gender)
#箱ひげ図作成
boxplot(split(x,group),col="gray")
#本実習で用いる独自関数群を読み込む
source("http://kyoto-edu.sakura.ne.jp/weblesson/statistics/socialStatisticsBasic.R")
#独自関数t.test.independent()を用いる
output.t.test2 <- t.test.independent(x~group)
#結果出力
output.t.test2
#ファイルへの書き出し
write.output(output.t.test2,"output.t.test2.csv")
t.test.independent関数(socialStatisticsBasic.Rで読み込まれる自作関数)
- t.test.independent(x~group,no1,no2)
-
- x=検定変数(間隔・比例尺度)
- group=グループ化変数(名義尺度)
- no1=グループの値
- no2=グループの値
※グループ化変数が2値とは限らないので、比較をしたい2グループを明示的に指定する。指定の無い時は出現順に上から二つの値を自動的に選択する。
write.output関数(socialStatisticsBasic.Rで読み込まれる自作関数)
- write.output(result,filename)
-
- result=Matrix型データのリスト
- filename=出力先ファイル名
出力結果( 形式)
形式)
$statistics
male female
N 244.000000 256.000000
mean 196.762295 175.417969
u 52.335504 58.951302
SE 3.350437 3.684456
Missing value 0.000000 0.000000
$test.result
t-test
t 4.285988e+00
df 4.955251e+02
p(!=) 2.186824e-05
p(>) 1.093412e-05
p(<) 9.999891e-01
mean diff 2.134433e+01
SE 4.980025e+00
Upper 3.112889e+01
Lower 1.155976e+01
d 3.823699e-01
r 1.890662e-01
- 平均の差の検定(両側)
- df = 495.53
- t = 4.29
- p(≠) = 0.00
- 効果量
- d = 0.38
- r = 0.19
主張( 形式)
形式)
t検定の結果から得られた知見をまとめよ。
データを読む:質的データの集計の主張テンプレを参考にせよ(用いる検定はχ2検定ではなく、(本ページ記載の)Welchのt検定である)。
- 主張例表示
-
スマートフォンの利用時間について、ジェンダー間で違いがあるのか。B大学の学生の中から無作為抽出を行い、1日あたりのスマートフォン利用時間について500人から回答を得た。このデータから性別に利用時間の平均差を取り上げる。
図表1 B大学学生のジェンダー別スマートフォン利用時間 female male 175.42 196.76 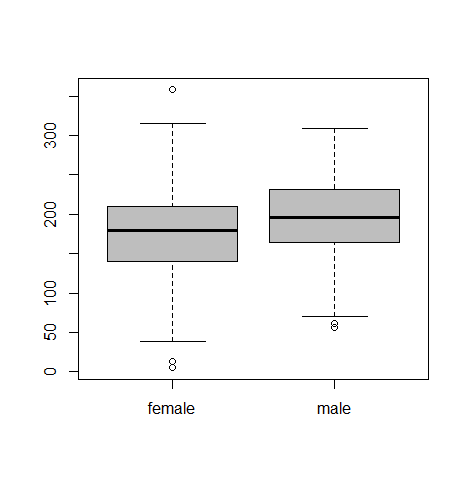
スマートフォンの利用時間はジェンダーにより差がある。B大学においてスマートフォンの利用時間は男子学生の方が女子学生よりも長い(t(495.53)=4.29, p<.05, d=0.38, r=0.19)。平均利用時間は男子学生196.76分、女子学生175.41分である。また分散は女子学生の方が大きく(女子学生 u2=58.95, 男子学生 u2=52.34)、女子学生は長く利用する学生とあまり利用しない学生の差が大きいことも分かる。
…上記結果と社会学理論(ジェンダー論など)・「常識」・その他の自身の知見を生かした自由な論証…
課題(形式)
μ国公立高校では特進コースと一般コースを設置している。公立高校においては高校間よりもコース間によって学力差があるとされている。
全国公立高校の生徒から無作為に200人を抽出し、統一学力試験(100点満点)を行った。本試験は国立大学共通入学テストに準じた内容となっている。この結果(μ国高校生コース別統一学力試験結果データ)から、μ国公立高校の受験学力について、どのような知見が得られるか、述べよ。