基本統計量
- 本章で用いる実習用ファイル
基本統計量とヒストグラム
基本統計量の中でも特に重要なのが代表値とデータの散らばり(散布度)である。
- 代表値…分布上の位置を表す
-
- 平均値…比例・間隔尺度・
順序尺度・名義尺度 - 中央値…比例・間隔尺度・順序尺度・
名義尺度 - 最頻値…比例・間隔尺度・順序尺度・名義尺度
- 最大値…比例・間隔尺度・順序尺度・
名義尺度 - 最小値…比例・間隔尺度・順序尺度・
名義尺度
cf.尺度
- 平均値…比例・間隔尺度・
- 散布度
-
- 範囲…最大値 - 最小値
- 分散…個々の値と平均値との偏差平方の平均
- 標準偏差…SQRT(分散)
| A | B | C | D | E | F | |
|---|---|---|---|---|---|---|
| 1 | No | 名前 | グループ | 身長 | 血液型 | |
| 2 | 1 | 中澤裕子 | モーニング娘。 | 158 | O | |
| 3 | 2 | 石黒彩 | モーニング娘。 | 160 | A | |
| 4 | 3 | 飯田圭織 | モーニング娘。 | 167 | A | |
| 5 | 4 | 安倍なつみ | モーニング娘。 | 152 | A | |
| 6 | 5 | 福田明日香 | モーニング娘。 | 149 | B | |
| 122 | 121 | 山﨑愛生 | モーニング娘。 | 159 | B | |
| 123 | 122 | 橋迫鈴 | アンジュルム | 152 | O | |
| 124 | ||||||
| 全データ | ||||||
- グループ(名義尺度)
- C2:C123
- 身長(比例尺度)
- D2:D123
- 血液型(名義尺度)
- E2:E123
各データセル範囲には項目名で名前定義をしている。
基本統計量
| G | H | I | J | |
|---|---|---|---|---|
| 1 | 統計量 | |||
| 2 | 人数(N) | =COUNT(身長) | ||
| 3 | 平均値(mean) | =AVERAGE(身長) | ||
| 4 | 中央値(median) | =MEDIAN(身長) | ||
| 5 | 最頻値(mode) | |||
| 6 | 最大値(max) | =MAX(身長) | ||
| 7 | 最小値(min) | =MIN(身長) | ||
| 8 | 範囲(range) | =H6 - H7 | ||
| 9 | 分散(V) | =VAR.P(身長) | ||
| 10 | 標準偏差(sd) | =STDEV.P(身長) | ||
| 11 | 不偏分散(u2) | =VAR.S(身長) | ||
| 12 | 標準偏差(u) | =STDEV.S(身長) | ||
| 13 |
分散と標準偏差
分散はデータの散らばり度合を表す統計量である。「範囲」と違って、全データの値を参照して算出される。
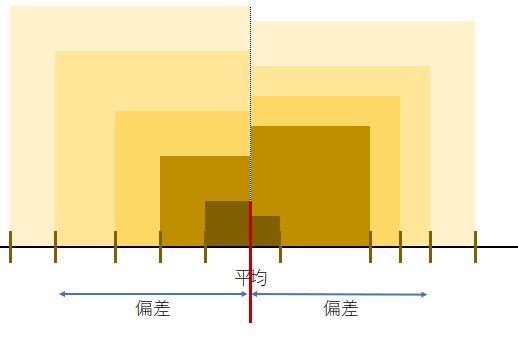
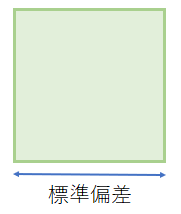
個々の値(身長)とその平均値(AVERAGE(身長))との差を偏差(身長-AVERAGE(身長))と呼ぶ。
この偏差を一辺とする正方形の面積が偏差平方((身長-AVERAGE(身長))^2)であり、そのN個の正方形の面積の総和が偏差平方和(SUM((身長-AVERAGE(身長))^2))である。
分散はこの偏差平方和を正方形の個数(N)(COUNT(身長))で割ったものである。つまり偏差を一辺とする正方形の面積の平均値が分散であり、その平方根を取ったもの(分散を面積とする正方形の一辺の長さ)が標準偏差である。
| D | F | G | H | I | J | |||
|---|---|---|---|---|---|---|---|---|
| 1 | 身長 | 偏差平方 | 統計量 | |||||
| 2 | 158 | =(身長-AVERAGE(身長))^2 | 人数 | 122 | ||||
| 3 | 160 | 4.829186375 | 平均値 | 157.80 | ||||
| 4 | 167 | 84.59476015 | 中央値 | 157 | ||||
| 8 | 145 | 163.9029569 | 分散 | =SUM((身長-AVERAGE(身長))^2)/COUNT(身長) | ||||
| 9 | 158 | 0.03902244 | 標準偏差 | =SQRT(I8) | ||||
| 122 | 159 | 1.434104407 | ||||||
| 123 | 152 | 33.66853064 | ||||||
| 124 |
ここでの数式はスピル配列を用いている。
- 分散
- 身長と身長の平均値(AVERAGE(身長))の差を二乗したものの合計(偏差平方和)を求め、それをデータの大きさ(N)で除算する。
- 標準偏差
- 分散の平方根を取ったもの。
Excelではこの分散はVAR.P関数で求められる。一方Excelには同じく分散を求める関数としてVAR.S関数がある。
このVAR.S関数で求められる分散を不偏分散と呼ぶ。不偏分散のなんたるか、どういうときに用いるのかは推測統計のときに説明する。
度数分布表とヒストグラム
名義尺度を変数として度数分布表を作るのは簡単(後述)。例えば血液型の度数分布表を作るには各血液型ごとの人数を数える。ExcelならばCOUNTIFS関数を用いるのが簡便である。
今回のように連続数を変数として度数分布表を作る時には、もう一手間が必要となる。変数を任意の区切り幅でカテゴリ―化してから度数分布表を作る。今回は身長を5cm区切りで設定する。この区切りを「ビン」と呼ぶ。
今回はビンを140(cm)を最小に、5(cm)区切りで設定した。
| 140-145 | 145-150 | 150-155 | 155-160 | 160-165 | 165-170 | 170-175 | 175-180 | 180-185 |
140-145の区切りは
- 140以上150未満
- 140より大きく150以下
という二つの方式があるが、日本では一般的に「140以上150未満」とするのが一般的なので、そちらを採択する。
| K | L | M | ||
|---|---|---|---|---|
| 2 | 人数 | |||
| 3 | 140 | |||
| 4 | 145 | |||
| 5 | 150 | |||
| 6 | 155 | |||
| 7 | 160 | |||
| 8 | 165 | |||
| 9 | 170 | |||
| 10 | 175 | |||
| 11 | 180 | |||
| 12 | 185 | |||
| 13 |
140-145に当てはまる人数を数えるには「身長>=140」かつ「身長<145」の条件に当てはまる「身長」の数値数を求める式を入力する。
Excelでは条件付き集計を行う。今回はその中から一番ベーシックな方法、COUNT関数とIF関数を組み合わせる方法を紹介する。
- セルL3
-
- 身長>=K3
- 身長<K4
この二つの条件を論理積で結ぶ。
- (身長>=K3)*(身長<K4)
この条件に当てはまる(TRUE)のとき、COUNT関数で数えられる値(ex.1)、FALSEの時はそのまま出力する。
- IF( (身長>=K3)*(身長<K4), 1)
この数式は「1」ないしは「FALSE」からなる配列を作る。140-145の階層には該当者がいないので、「FALSE」だけが並ぶ。例えば155-160の階層の場合(IF( (身長>=K6)*(身長<K7), 1))、配列は下のようになる。
No 1 2 3 4 5 6 7 … 122 1 FALSE FALSE FALSE FALSE 1 FALSE … FALSE この配列で数値(「1」)が入っている数を数える。
- COUNT(IF( (身長>=K3)*(身長<K4), 1))
- セルL4以降
-
セルL4をオートフィルでコピーする。
| K | L | M | ||
|---|---|---|---|---|
| 2 | 人数 | |||
| 3 | 140 | =COUNT(IF( (身長>=K3)*(身長<K4), 1)) | ||
| 4 | 145 | 3 | ||
| 5 | 150 | 35 | ||
| 6 | 155 | 41 | ||
| 7 | 160 | 30 | ||
| 8 | 165 | 11 | ||
| 9 | 170 | 1 | ||
| 10 | 175 | 0 | ||
| 11 | 180 | 1 | ||
| 12 | 185 | 0 | ||
| 13 |
直接身長データからヒストグラムを作成できるが(「140より大きく150以下」方式のみ)、今回は度数分布表からヒストグラムを作る。
| K | L | M | ||
|---|---|---|---|---|
| 2 | 人数 | |||
| 3 | 140 | 0 | ||
| 4 | 145 | 3 | ||
| 5 | 150 | 35 | ||
| 6 | 155 | 41 | ||
| 7 | 160 | 30 | ||
| 8 | 165 | 11 | ||
| 9 | 170 | 1 | ||
| 10 | 175 | 0 | ||
| 11 | 180 | 1 | ||
| 12 | 185 | 0 | ||
| 13 |
- 度数分布表(セルK2:L12)をアクティブセルにする
- グラフを挿入する
- [おすすめグラフ]ボタンをクリックする
[挿入]→[グラフ] ![[挿入]→[グラフ]](/weblesson/office/image/excelGraph01.png)
- グラフの種類を選択する
[集合縦棒] ![[すべてのグラフ]→[縦棒]→[集合縦棒]](/weblesson/office/image/excelGraph02.png)
[集合縦棒]を選択する
- [おすすめグラフ]ボタンをクリックする
- 棒のデザインを修正する
- 作られたグラフの[データ要素](縦棒)をダブルクリックする
集合縦棒グラフ(初期) 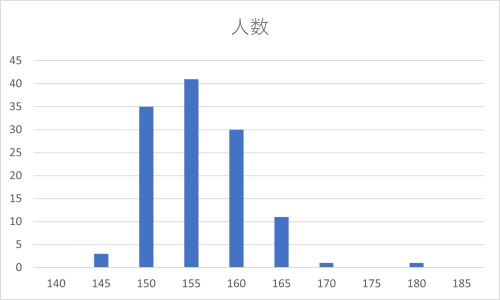
- [要素の間隔]を「0%」に指定する
系列のオプション ![[要素の間隔]:0%](/weblesson/statistics/image/excelDescriptive02.png)
ウィンドウ右側に出る「書式設定」画面から[系列のオプション][系列のオプション][要素の間隔]を「0%」とする
- [枠線]を設定する
系列のオプション ![[枠線(単色)][色]:白](/weblesson/statistics/image/excelDescriptive03.png)
[枠線]より[枠線(単色)]・[色]→白を選択する
- 作られたグラフの[データ要素](縦棒)をダブルクリックする
- タイトルを修正して完成
ヒストグラム(完成) ![[タイトル]:身長のヒストグラム](/weblesson/statistics/image/excelDescriptive04.png)
最頻値
「最頻値」は難物である。順序尺度・名義尺度の時は単純に同じ値の数を数えれば最頻値が求められるが、比例・間隔尺度においてはそれではあまり実用にならない(ExcelのMODE系関数は使えない)。一定の区切り幅の中で度数の高い区間から求める方が実用的である。このような最頻値は先に作成した度数分布表を元に求める。
| K | L | M | ||
|---|---|---|---|---|
| 2 | 人数 | |||
| 3 | 140 | 0 | ||
| 4 | 145 | 3 | ||
| 5 | 150 | 35 | ||
| 6 | 155 | 41 | ◀ | |
| 7 | 160 | 30 | ||
| 8 | 165 | 11 | ||
| 9 | 170 | 1 | ||
| 10 | 175 | 0 | ||
| 11 | 180 | 1 | ||
| 12 | 185 | 0 | ||
| 13 |
- 一番大きい度数(41)を見つける
- それに対応する区切り(155-160)を探す
- その範囲の中央値(157.5)を最頻値とする
- 度数が一番大きい区切りが複数あるとき(150-155の区切りにも41人いた場合)、すべての中央値の平均値を最頻値とする。
実用的には区切りを目視で探して、暗算でよいが、式で求める場合は以下のようにする。
- 度数の最大値を求める:MAX(L3:L12)
- 対応する区切りを探す
- 度数の最大値に対応する区切りを判定する
K L M N O 2 人数 3 140 0 =L3:L12=MAX(L3:L12) 4 145 3 FALSE 5 150 35 FALSE 6 155 41 TRUE 7 160 30 FALSE 8 165 11 FALSE 9 170 1 FALSE 10 175 0 FALSE 11 180 1 FALSE 12 185 0 FALSE 13 - 最大値に対応する区切りの始点の数値を配列に入れる
K L M N O 2 人数 3 140 0 FALSE =IF(M3#,K3:K12) 4 145 3 FALSE FALSE 5 150 35 FALSE FALSE 6 155 41 TRUE 155 7 160 30 FALSE FALSE 8 165 11 FALSE FALSE 9 170 1 FALSE FALSE 10 175 0 FALSE FALSE 11 180 1 FALSE FALSE 12 185 0 FALSE FALSE 13
- 度数の最大値に対応する区切りを判定する
- その区切りの中央値を求める(区切りの始点に区切り幅を2で除算した値を足したものが中央値である)
K L M N O 2 人数 3 140 0 FALSE =IF(M3#,K3:K12+(K4-K3)/2) 4 145 3 FALSE FALSE 5 150 35 FALSE FALSE 6 155 41 TRUE 157.5 7 160 30 FALSE FALSE 8 165 11 FALSE FALSE 9 170 1 FALSE FALSE 10 175 0 FALSE FALSE 11 180 1 FALSE FALSE 12 185 0 FALSE FALSE 13 - この中央値の配列の平均値が最頻値となる。
K L M N O 2 人数 3 140 0 FALSE FALSE 4 145 3 FALSE FALSE 5 150 35 FALSE FALSE 6 155 41 TRUE 157.5 7 160 30 FALSE FALSE 8 165 11 FALSE FALSE 9 170 1 FALSE FALSE 10 175 0 FALSE FALSE 11 180 1 FALSE FALSE 12 185 0 FALSE FALSE 13 13 最頻値 =AVERAGE(N3:N12)
- 最頻値
-
=AVERAGE(IF(L3:L12=MAX(L3:L12), K3:K12 + (K4 - K3)/2))K L M 2 人数 3 140 0 4 145 3 5 150 35 6 155 41 7 160 30 8 165 11 9 170 1 10 175 0 11 180 1 12 185 0 13 - 基本統計量まとめ
-
G H I J 1 統計量 2 人数(N) =COUNT(身長) 3 平均値(mean) =AVERAGE(身長) 4 中央値(median) =MEDIAN(身長) 5 最頻値(mode) =AVERAGE(IF(度数=MAX(度数),各ビンの始点 + ビンの幅/2)) 6 最大値(max) =MAX(身長) 7 最小値(min) =MIN(身長) 8 範囲(range) =H6-H7 9 分散(V) =VAR.P(身長) 10 標準偏差(sd) =STDEV.P(身長) 11 不偏分散(u2) =VAR.S(身長) 12 標準偏差(u) =STDEV.S(身長) 13
グループ別集計
基本統計量
カテゴリーごとに統計量を求めるときには条件付き集計を行う。
| H | I | J | K | L | M | N | O | ||
|---|---|---|---|---|---|---|---|---|---|
| 15 | グループ | 人数 | 平均 | 分散 | 最大 | 最小 | 中央値 | ||
| 16 | |||||||||
| 17 | |||||||||
| 18 | |||||||||
| 25 | 合計 | 122 | 157.80 | 29.93 | 182.0 | 145.0 | 157.0 | ||
| 26 |
カテゴリー変数は漏らさず、ダブらないようにリスト化する必要がある。ExcelではUNIQUE関数を用いる。
重複しない値:UNIQUE(配列)
UNIQUE関数は配列から重複しない値を返す関数である。
| H | |||
|---|---|---|---|
| 15 | グループ | ||
| 16 | =UNIQUE(グループ) | ||
| 17 | Berryz工房 | ||
| 18 | ℃-ute | ||
| 19 | アンジュルム | ||
| 20 | カントリー・ガールズ | ||
| 21 | Juice=Juice | ||
| 22 | こぶしファクトリー | ||
| 23 | つばきファクトリー | ||
| 24 | BEYOOOOONDS | ||
| 25 | 合計 | ||
| 26 |
データの並び順は元配列の並び順に依存する。
条件付き集計
Excelには条件付き集計を行うための機能としてIFS関数群が用意されている(COUNTIFS, SUMIFS, AVERAGEIFS, MAXIFS, MINIFS)。ただこの関数群だけでは足りない。具体的には中央値・分散などが求められない。
そこでここでは度数分布表と同様IF関数と集計関数を合わせて用いる。
データの大きさN(人数)
| H | I | |||
|---|---|---|---|---|
| 15 | グループ | 人数 | ||
| 16 | モーニング娘。 | =COUNT(IF(グループ=H16, 1)) | ||
| 17 | Berryz工房 | 8 | ||
| 18 | ℃-ute | 8 | ||
| 19 | アンジュルム | 18 | ||
| 20 | カントリー・ガールズ | 6 | ||
| 21 | Juice=Juice | 9 | ||
| 22 | こぶしファクトリー | 8 | ||
| 23 | つばきファクトリー | 9 | ||
| 24 | BEYOOOOONDS | 12 | ||
| 25 | 合計 | =COUNT(グループ) | ||
| 26 |
平均値 mean
| H | J | ||||
|---|---|---|---|---|---|
| 15 | グループ | 平均値 | |||
| 16 | モーニング娘。 | =AVERAGE(IF(グループ=H16, 身長)) | |||
| 17 | Berryz工房 | 161.65 | |||
| 18 | ℃-ute | 158.80 | |||
| 19 | アンジュルム | 158.33 | |||
| 20 | カントリー・ガールズ | 152.50 | |||
| 21 | Juice=Juice | 159.14 | |||
| 22 | こぶしファクトリー | 157.25 | |||
| 23 | つばきファクトリー | 158.54 | |||
| 24 | BEYOOOOONDS | 158.57 | |||
| 25 | 合計 | =AVERAGE(グループ) | |||
| 26 |
分散 V
| H | K | ||||
|---|---|---|---|---|---|
| 15 | グループ | 分散 | |||
| 16 | モーニング娘。 | =VAR.P(IF(グループ=H16, 身長)) | |||
| 17 | Berryz工房 | 82.94 | |||
| 18 | ℃-ute | 36.53 | |||
| 19 | アンジュルム | 19.00 | |||
| 20 | カントリー・ガールズ | 7.58 | |||
| 21 | Juice=Juice | 14.81 | |||
| 22 | こぶしファクトリー | 22.63 | |||
| 23 | つばきファクトリー | 17.94 | |||
| 24 | BEYOOOOONDS | 31.73 | |||
| 25 | 合計 | =VAR.P(グループ) | |||
| 26 |
最大値 max
| H | L | ||||
|---|---|---|---|---|---|
| 15 | グループ | 最大値 | |||
| 16 | モーニング娘。 | =MAX(IF(グループ=H16, 身長)) | |||
| 17 | Berryz工房 | 182 | |||
| 18 | ℃-ute | 170 | |||
| 19 | アンジュルム | 166 | |||
| 20 | カントリー・ガールズ | 157 | |||
| 21 | Juice=Juice | 165 | |||
| 22 | こぶしファクトリー | 163.5 | |||
| 23 | つばきファクトリー | 167 | |||
| 24 | BEYOOOOONDS | 168 | |||
| 25 | 合計 | =MAX(グループ) | |||
| 26 |
最小値 min
| H | M | ||||
|---|---|---|---|---|---|
| 15 | グループ | 最小値 | |||
| 16 | モーニング娘。 | =MIN(IF(グループ=H16, 身長)) | |||
| 17 | Berryz工房 | 150 | |||
| 18 | ℃-ute | 152 | |||
| 19 | アンジュルム | 152 | |||
| 20 | カントリー・ガールズ | 148 | |||
| 21 | Juice=Juice | 153.3 | |||
| 22 | こぶしファクトリー | 150 | |||
| 23 | つばきファクトリー | 153 | |||
| 24 | BEYOOOOONDS | 150 | |||
| 25 | 合計 | =MIN(グループ) | |||
| 26 |
中央値 median
| H | N | ||||
|---|---|---|---|---|---|
| 15 | グループ | 中央値 | |||
| 16 | モーニング娘。 | =MEDIAN(IF(グループ=H16, 身長)) | |||
| 17 | Berryz工房 | 160 | |||
| 18 | ℃-ute | 157 | |||
| 19 | アンジュルム | 159.5 | |||
| 20 | カントリー・ガールズ | 152.5 | |||
| 21 | Juice=Juice | 160 | |||
| 22 | こぶしファクトリー | 157.5 | |||
| 23 | つばきファクトリー | 159 | |||
| 24 | BEYOOOOONDS | 158 | |||
| 25 | 合計 | =MEDIAN(グループ) | |||
| 26 |
箱ひげ図
分布をグループごとに視覚的に比較するときには箱ひげ図を用いる。
| A | B | C | D | E | F | |
|---|---|---|---|---|---|---|
| 1 | No | 名前 | グループ | 身長 | 血液型 | |
| 2 | 1 | 中澤裕子 | モーニング娘。 | 158 | O | |
| 3 | 2 | 石黒彩 | モーニング娘。 | 160 | A | |
| 4 | 3 | 飯田圭織 | モーニング娘。 | 167 | A | |
| 5 | 4 | 安倍なつみ | モーニング娘。 | 152 | A | |
| 6 | 5 | 福田明日香 | モーニング娘。 | 149 | B | |
| 122 | 121 | 山﨑愛生 | モーニング娘。 | 159 | B | |
| 123 | 122 | 橋迫鈴 | アンジュルム | 152 | O | |
| 124 |
Excelで箱ひげ図を作る際、量的変数(「身長」)とグループ化変数(「グループ」)が並んでいると両者を一つの範囲選択すれば簡単に作成できるが、いつもそうであるとは限らない(「身長」と「血液型」)。今回はグループで箱ひげ図を作るが、敢えて一般的なやり方を説明する。
- セル範囲D1:D123をアクティブセルにする
- グラフを挿入する
- [おすすめグラフ]ボタンをクリックする
[挿入]→[グラフ]
- グラフの種類を選択する
[箱ひげ図] ![[すべてのグラフ]→[箱ひげ図]→[箱ひげ図]](/weblesson/statistics/image/excelDescriptive05.png)
[箱ひげ図]を選択する
- [おすすめグラフ]ボタンをクリックする
- データ範囲を修正する(連続する範囲選択した場合は不要)
- [グラフデザイン]リボン中の[データ]グループにある[データの選択]ボタンをクリックする
[データの選択]ボタン ![[グラフデザイン]→[データ]→[データの選択]](/weblesson/statistics/image/excelDescriptive06.png)
- [データソースの選択]ダイアログボックスより[横(項目)軸ラベル]の[編集]ボタンをクリックする
[データソースの選択]ダイアログボックス ![[データソースの選択][横(項目)軸ラベル][編集]](/weblesson/statistics/image/excelDescriptive07.png)
- [軸ラベルの範囲]を設定する
[軸ラベル] ![[軸ラベルの範囲]:=記述統計!$C$2:$C$123](/weblesson/statistics/image/excelDescriptive08.png)
[軸ラベルの範囲]欄にグループ化変数の範囲を入力する(=記述統計!
![[凡例項目(系列)]:身長, [横(項目)軸ラベル]:モーニング娘。モーニング娘。モーニング娘。モーニング娘。モーニング娘。](/weblesson/statistics/image/excelDescriptive09.png)
箱ひげ図 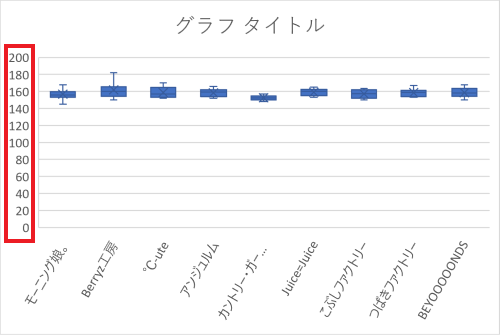
縦軸が見えなくなることがあるが、グラフの大きさを変更すると現れる。
- [グラフデザイン]リボン中の[データ]グループにある[データの選択]ボタンをクリックする
- 縦軸を修正する
- 縦軸をダブルクリックする
- [軸の書式設定]画面より[軸のオプション]の[最小値]と[最大値]を適宜修正する
[軸の書式設定] ![[最小値]:140,[最大値]:190](/weblesson/statistics/image/excelDescriptive11.png)
- タイトルを修正して完成
箱ひげ図 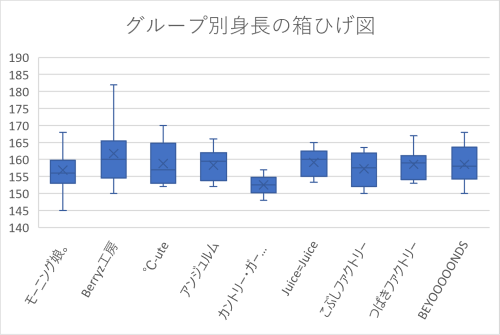
グループごとの分布の特徴を一瞥できる。