相関係数
- 本章で用いる実習用ファイル
ある集団から無作為に選んだ326人に学力テストを行い、その点数を記録し、さらに受験者のさまざまな属性と合わせて結果を分析することにした。
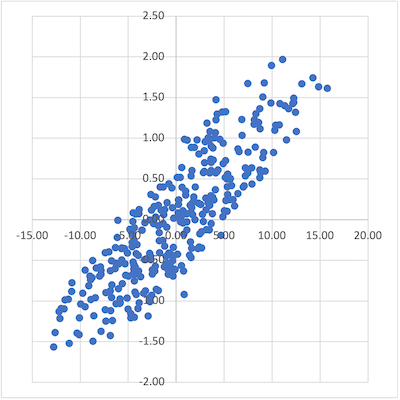
Aさんはその中から受験者の身長と試験結果との関連を分析し、「身長が高ければ、試験で高い点数を取れる」と結論付けた。
このAさんの分析を追試し、批評せよ。
| A | B | C | D | |||
|---|---|---|---|---|---|---|
| 1 | no | marks | height | age | ||
| 2 | 1 | 50 | 122.06 | 8.6 | ||
| 3 | 2 | 76 | 153.21 | 12.0 | ||
| 4 | 3 | 43 | 117.53 | 7.2 | ||
| 5 | 4 | 51 | 127.56 | 8.4 | ||
| 6 | 5 | 30 | 109.83 | 6.0 | ||
| … | ||||||
| 被験者諸属性と試験結果(架空データ) | ||||||
- marks(比例尺度)
- B2:B327
- height(比例尺度)
- C2:C237
- age(比例尺度)
- D2:D237
量的な変数が複数ある時、この変数間の関係の強度を表す統計量が相関係数である。相関係数は関係の強さと方向性を示す。
散布図
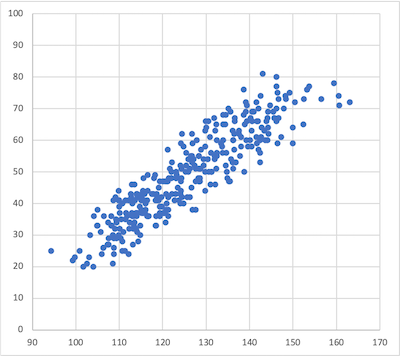
散布図からは身長の高さと点数には関係があるように見える。身長が高い時には点数も高い。この関係を「正の相関がある」という。
相関係数
| H | I | |||
|---|---|---|---|---|
| … | ||||
| 3 | 偏差積和 | 55975.39 | ||
| 4 | 共分散Cov | 172.23 | ||
| 5 | 身長の標準偏差 | 13.50 | ||
| 6 | 点数の標準偏差 | 14.09 | ||
| 7 | 相関係数r | 0.91 | ||
| … |
偏差積和と共分散
| H | I | |||
|---|---|---|---|---|
| … | ||||
| 3 | 偏差積和 | =SUM((height - AVERAGE(height))*(marks - AVERAGE(marks))) | ||
| 4 | 共分散Cov | =I3/(COUNT(height)-1) | ||
| … |
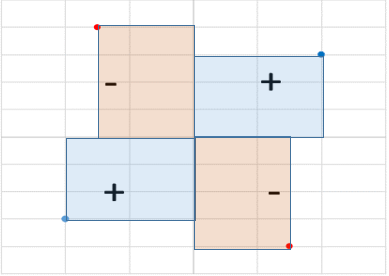
分散Varianceが1変数とその平均の差を一辺とする正方形の面積(偏差平方)の平均であるのに対して、共分散Covarianceは2変数の各々の平均との差を一辺とする長方形の面積(偏差積)の平均である。
ただし偏差積は負の値を取り得る。
相関係数
| H | I | |||
|---|---|---|---|---|
| … | ||||
| 4 | 共分散Cov | 172.23 | ||
| 5 | 身長の標準偏差 | =SQRT(SUM((height-AVERAGE(height))^2)/(COUNT(height)-1)) | ||
| 6 | 点数の標準偏差 | =SQRT(SUM((marks-AVERAGE(marks))^2)/(COUNT(marks)-1)) | ||
| 7 | 相関係数r | =I4/(I5*I6) | ||
| … |
共分散は各々の変数の分散により、その大きさが変わる。それを統制し、各変数の散らばりの規模に依存しない値としたものが相関係数である。平均差を標準偏差で統制しているので、相関係数の絶対値は1を超えることはない。
もはや変数一つ一つの散らばりの規模には影響しない相関係数は変数1と変数2の関係に対する統計量となる。長方形の面積が正で占めれば相関係数も大きな値(<=1)となり、負で占めれば相関係数も小さな値(>=-1)を取る。また正負が拮抗すれば相関係数は0に近づく。
相関係数はサンプルサイズには依存しない統計量である。つまりこれは効果量と見なすことが出来る。
| 効果量rの絶対値 | 効果の目安 |
|---|---|
| 0.5 | 大 |
| 0.3 | 中 |
| 0.1 | 小 |
| 0 | なし |
相関係数の効果の目安はケースバイケースで判断するしかない。表は社会科学系での目安となる。自然科学系よりもrの数値が小さくても大きめの影響を見積もることが多い。
無相関検定
効果量はサンプルサイズの大きさにより、その有意性の判断は変わる。サンプルサイズが十分大きければ、効果量が小さな値でも有意となり得るし、サンプルサイズが小さければ、効果量が大きな値でも有意とならないかも知れない。有意性とは効果の大小とは別に、サンプリングによる偏りによってその効果が偶然的に生じうるのか否かを判断する指標である。
※仮に統計的に「有意」と判断できたとしても、効果があまりに小さければ、結果的にそれは意味が乏しいということも当然あり得る。統計的に有意だから「意味がある」というわけではない。
| H | I | |||
|---|---|---|---|---|
| … | ||||
| 7 | 相関係数r | 0.91 | ||
| 8 | 決定係数R2 | =I7^2 | ||
| 9 | 自由度 | =COUNT(height) - 2 | ||
| 10 | 標準誤差SE | =SQRT((1 - I8)/I9) | ||
| 11 | t | =I7/I10 | ||
| 12 | p(≠) | =(1 - T.DIST(ABS(I11),I9,TRUE))*2 | ||
| … |
- 相関係数の有意性を判断する際には、相関係数が二つの変数双方の平均値を規定のものとして求められているので、その分を差し引いたサンプルサイズ - 2が自由度となる。
- 相関係数を2乗した値を決定係数と呼ぶ。二つの変数双方の分散を掛け合わせたデータ全体のばらつきに対して2変数が協調するばらつき(共分散)の割合を示したものである。
- 1から決定係数を引いたものが相関関係の影響の外にあるデータのばらつき、すなわち残差となる。この残差をデータ量(自由度)で割り、平方根をとったものが相関係数の標準誤差である。
- 「相関係数が0と等しい」を帰無仮説とする無相関検定の検定統計量tは相関係数rを標準誤差で割ったものである。相関関係の標準誤差に対して相関係数が十分大きければ有意となるような値である。
- 後はおなじみのp値。「相関係数が0と等しい」を帰無仮説=「相関係数は0ではない」を対立仮説とするので両側検定。「相関係数が正または負である」ということを対立仮説とする場合は片側検定となる。
疑似相関と偏相関係数
成績と身長の相関係数は0.91、強い相関があり、サンプルサイズが326あるので、無相関検定でもp=0.00、有意。つまり成績と身長には正の相関がある。Aさんはさらに踏み込んで身長を「原因」と述べているのも「成績→身長」という因果は想定しづらい以上、妥当であろう。
え?ほんと!?身長が高ければ成績が上がる、という結論でいいの?
そういえば「朝食を取る生徒は成績がいい。だから朝食を食べよう」みたいなキャンペーンがあったなあ。あれもなんか怪しかったんだが。
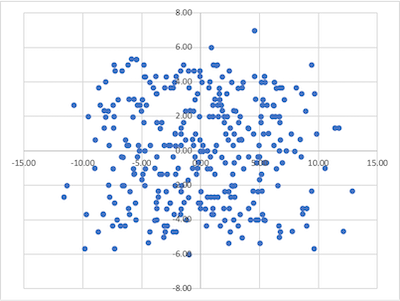
そういえばこのデータ、点数と身長以外にも年齢という変数があったなあ。というか、このデータ、年齢を見てみれば子どものデータじゃん。
子どものデータなら年齢が高ければ身長も高くなるだろうし、得点も高くなる、というのはあり得そうだ。
- 年齢は点数に影響を及ぼしている?
年齢と点数の散布図 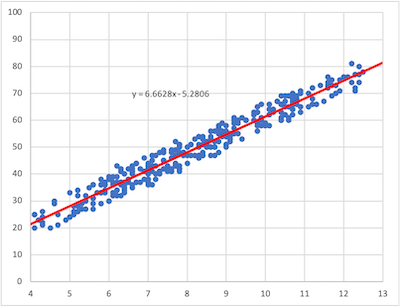
- 相関係数
-
H I … 17 年齢*点数r 0.98 … - 近似直線
-
H I … 21 点数~年齢傾きb 6.66 22 点数~年齢切片a -5.28 …
- 年齢は身長に影響を及ぼしている?
年齢と身長の散布図 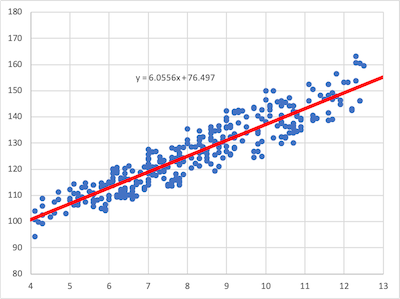
- 相関係数
-
H I … 18 年齢*身長r 0.93 … - 近似直線
-
H I … 23 身長~年齢傾きb 6.06 24 身長~年齢切片a 76.50 …
年齢と点数、年齢と身長の間に正の相関関係が見られる。
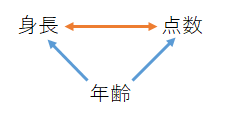
年齢→点数、年齢→身長という影響を排除して、点数と身長の相関を調べる
年齢によって点数が決まる、年齢で身長が決まる、双方の予測値(分散分析におけるカテゴリごとの平均値に相当)は近似直線によってあたえられる。そしてこの予測値と実測値の差が年齢の影響を排除した点数・身長の値(年齢からの残差)である。この年齢の影響を排除した点数・身長の値の相関を取ったものが偏相関となる。
近似直線は切片aと傾きbによって決まる。
近似直線
相関係数が1または-1に近づく時というのはある直線にすべての実測値が重なる時である。このときこの直線を近似直線と呼ぶ。
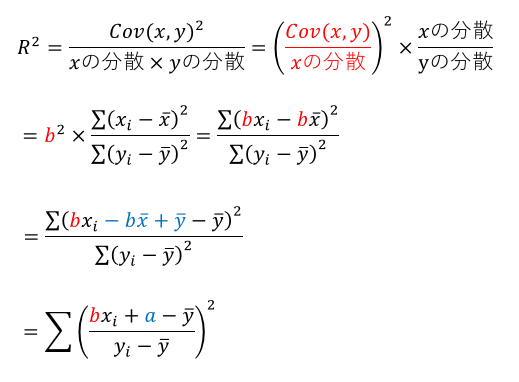
a+bx_i→y_i ならばR^2=1
つまり実測値(xi,yi)が直線
y = a + bx (a=mean(y) - b*mean(x), b=Cov(x,y)/var(x))
に接近すればするほど相関係数rは1または-1に近づく。
点数・身長データから年齢による変化(y = a + b×年齢データ)を引いた値を求める。
| E | F | |||
|---|---|---|---|---|
| 1 | 点数(年齢統制) | 身長(年齢で統制) | ||
| 2 | =marks-($I$22+$I$21*age) | =height-($I$24+$I$23*age) | ||
| 3 | 1.33 | 4.05 | ||
| 4 | 0.31 | -2.57 | ||
| 5 | 0.31 | 0.20 | ||
| 6 | -4.70 | -3.00 | ||
| … |
- 年齢で統制した点数と身長の偏相関係数
-
H I … 25 点数*身長 =CORREL(E2:E327,F2:F327) …
あれれ?相関が消えた!?
見事に相関が消えている。
年齢があがると身長と点数、双方が引き上げられ、結果として身長と点数にも正の相関関係が出てしまったということ。年齢が等しいもの同士では身長が高かろうが点数に影響が出ていない。このような相関を疑似相関と呼ぶ。
年齢の影響を排除して出てきた身長と点数の相関係数を「年齢で統制した身長と点数の偏相関係数 partial correlation coefficient」と呼ぶ。
点数、身長、年齢相互に正の相関があるから、年齢で統制すれば身長・点数の相関が消えるというのなら、同じく身長で統制すれば年齢・点数の相関も消えるの?
| H | I | |||
|---|---|---|---|---|
| … | ||||
| 2 | 点数~身長傾きb | 0.95 | ||
| 3 | 点数~身長切片a | -69.95 | ||
| 4 | 年齢~身長傾きb | 0.14 | ||
| 5 | 年齢~身長切片a | -9.70 | ||
| … |
| E | F | |||
|---|---|---|---|---|
| 1 | 点数(身長統制) | 年齢(身長で統制) | ||
| 2 | =marks-($I$3+$I$2*height) | =age-($I$5+$I$4*height) | ||
| 3 | 1.12 | -0.03 | ||
| 4 | 1.85 | 0.23 | ||
| 5 | 0.37 | 0.01 | ||
| 6 | -3.87 | 0.12 | ||
| … |
- 身長で統制した点数と年齢の偏相関係数
-
H I … 8 点数*年齢r =CORREL(E2:E327,F2:F327) …
考察例
Aさんは疑似相関を真正の相関と見なしたところが間違っている。Aさんは身長と点数のみで相関係数を求めたが、Aさんは年齢と身長・点数の関係についての考察を行っていない。しかし年齢と身長・点数には非常に高い相関関係が見られた。そこで身長と点数の関係を年齢で統制して、身長と点数の偏相関係数を求めた。その結果、身長と点数の相関には有意差が出ない。つまり身長と点数は年齢を媒介とした疑似相関であると言える。
このデータから読み取れる結論は「年齢が高い方が試験で高い点を取る傾向がある」と言うことである。