独立した2グループ間での平均の差の検定
- 本章で用いる実習用ファイル
2グループ間での平均差
B大学の学生の中から500人を無作為抽出を行い、スマートフォン利用時間について調べたデータからスマートフォン利用時間に関するジェンダー差を知りたい。
下記データより、B大学の学生のスマートフォン利用時間について、男子学生と女子学生の違いについてデータから得られる知見を述べよ。
| A | B | C | D | E | F | G | H | I | J | |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | No | gender | faculty | time | 偏差平方 | male | female | |||
| 2 | 1 | female | science | 193 | N | |||||
| 3 | 2 | female | law | 166 | df | |||||
| 4 | 3 | male | science | 293 | mean | |||||
| 5 | 4 | female | literature | 135 | u2 | |||||
| μ国B大学スマートフォン利用時間調査データ | ||||||||||
- gender(名義尺度)
- B2:B501
- time(比例尺度)
- D2:D501
- SDM(比例尺度)
- E2:E501
問1
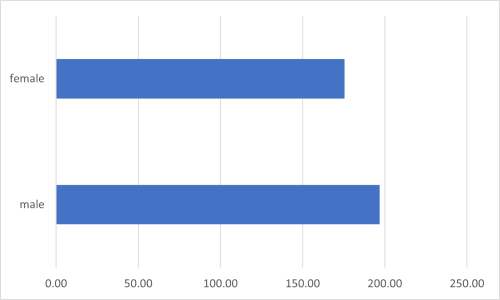
データより男女別の平均値を算出し、棒グラフで比較せよ。
結果出力例-1
| male | female |
|---|---|
| 196.76 | 175.42 |
問2
- 結果より、男女に差があると言えるのか、統計的手法(独立した2グループ間での平均の差の検定)を用いて検証せよ。
- 効果量rを求め、平均差の意義を確認せよ。
- 差に意義があるとすれば、統計的結果に基づき「記述・推測的解釈」を行え。
- 「記述・推測的解釈」を元に、問題文の文脈を加えて、「批評的解釈」を行え。
主張テンプレート
…トピックセンテンス(主張)…。B大学においてスマートフォンの利用時間は○子学生の方が×子学生よりも長い(t(◆)=●, p< .05, r=▲)。平均利用時間は男子学生x分、女子学生y分である。
- ◆…自由度
- ●…t値
- ▲…効果量
Studentのt検定
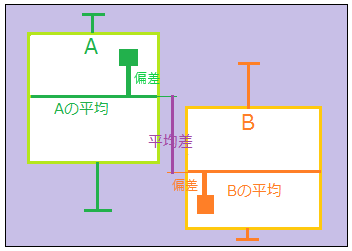
これまでのt検定と同様、二つのグループの平均値の差がサンプルの偶然的なばらつき(=標準誤差)に由来する偏りによって生じたものとは説明できないぐらいに十分に大きければ有意とする。
1グループの時にはデータのばらつきも一つのグループのみを考えれば良かったが、2グループの時には各々のばらつきを扱わなければならない。そこが苦心のしどころ。
- 主張(対立仮説)
- グループの違いによって、個々の値が変わる(→その集約としての平均値が異なる)。
- 主張する際の障壁(帰無仮説)
- 個々の値はグループの違いとは別の理由(偶然)によってばらついている(グループの違いなんて些細なこと)。
双方のグループ内部でのばらつきが大きければ、グループ間の平均差はばらつきの中に埋もれる。逆にばらつきが小さいと、グループ間の平均差が意味を持つ。
これまではグループを分けずに、サンプル全体の平均値と個別の値の差(偏差)からデータのばらつき(分散)を計算してきた。今回はグループごとに平均値が異なるので、それを考慮に入れて、分散を計算する。
- 共通分散
-
- 各グループ内で平均値を出し、各グループのデータとの差(偏差 Deviations from the Mean)を計算する。
B D E F G H I J 1 gender time 偏差 male female 2 female 193 =time-IF(gender="male",H4,I4) N 244 256 3 female 166 df 243 255 4 male 293 mean 196.76 175.42 5 female 135 u2 2739.00 3475.26 maleグループはmaleのデータのみで平均値を出し(H4)、maleに属する個別のtimeデータとの差を計算する。femaleグループも同様の計算をする。
- 偏差を2乗して散らばりの大きさ(偏差平方 Squared Deviations from the Mean)を求める。
B D E F G H I J 1 gender time 偏差平方SDM male female 2 female 193 =(time-IF(gender="male",H4,I4))^2 N 244 256 3 female 166 df 243 255 4 male 293 mean 196.76 175.42 5 female 135 u2 2739.00 3475.26 - 全データの偏差平方を合計する(偏差平方和 Sum of Squared Deviations from the Mean)。
G H I 10 偏差平方和SS =SUM(SDM) - 偏差平方和を自由度で割る(共通分散)。このデータはmaleの平均値とfemaleの平均値二つの値を規定のものとしているので、自由度はサンプルサイズ - 2(あるいはmaleの自由度 + femaleの自由度)である。
G H I 10 共通分散 =SUM(SDM)/SUM(H3:I3) この共通分散がグループ間の平均差の影響を排除した(グループ間の平均差を統制した)データのばらつき(分散)である。
- 各グループ内で平均値を出し、各グループのデータとの差(偏差 Deviations from the Mean)を計算する。
- 標準誤差
-
グループごとに分散(共通分散)をサンプルサイズで割ったものがグループごとのサンプルの平均値のばらつきとなる。それを足して平方根を取ったものが2グループを併せた標準誤差となる。
G H I 10 共通分散 3116.00 11 標準誤差SE =SQRT(H10/H2+H10/I2) - 検定統計量t値
-
標準誤差が求められた後はこれまでのt検定と同じ。平均差を標準誤差の水準で補正した値(検定統計量t)が、(偶然では生じえないほど)十分大きければ有意。
G H I 9 平均差 21.34 11 標準誤差 4.99 12 t値 =H9/H11
- 共通分散 ← (グループ1の偏差平方和 + グループ2の偏差平方和) / (グループ1の自由度 + グループ2の自由度)
- 標準誤差 ← SQRT(共通分散/グループ1のサンプルサイズ + 共通分散/グループ2のサンプルサイズ)
- 検定統計量t ← (グループ1の平均値 - グループ2の平均値) / 標準誤差
- p値
-
G H 12 t値 4.27 13 自由度 498 14 p値(≠) =(1-T.DIST(ABS(H12),H13,TRUE))*2 15 p値(>) =1-T.DIST(H12,H13,TRUE) 16 p値(<) =T.DIST(H12,H13,TRUE) - 信頼区間
-
G H 8 有意水準 5% 9 平均差 21.34 10 共通分散 3116.00 11 標準誤差 4.99 13 自由度 498 17 信頼上限 =H9 + T.INV(1 - H8/2, H13)*H11 18 信頼下限 =H9 - T.INV(1 - H8/2, H13)*H11 - 効果量
-
G H 9 平均差 21.34 10 共通分散 3116.00 12 t値 4.27 13 自由度 498 19 効果量d =H9/SQRT(H10) 20 効果量r =SQRT(H12^2/(H12^2+H13))
結果出力例
| G | H | I | |||
|---|---|---|---|---|---|
| 1 | male | female | |||
| 2 | N | 244 | 256 | ||
| 3 | df | 243 | 255 | ||
| 4 | mean | 196.76 | 175.42 | ||
| 5 | u2 | 2739.00 | 3475.26 | ||
| 7 | t検定 | ||||
| 8 | 有意水準 | 5% | |||
| 9 | 平均差 | 21.34 | |||
| 10 | 共通分散 | 3116.00 | |||
| 11 | 標準誤差 | 4.99 | |||
| 12 | t値 | 4.27 | |||
| 13 | 自由度 | 498 | |||
| 14 | p値(≠) | 0.00 | |||
| 15 | p値(>) | 0.00 | |||
| 16 | p値(<) | 1.00 | |||
| 17 | 信頼上限 | 31.16 | |||
| 18 | 信頼下限 | 11.53 | |||
| 19 | 効果量d | 0.38 | |||
| 20 | 効果量r | 0.19 | |||
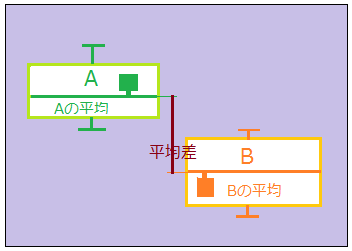
Welchのt検定
Studentのt検定(1908)ではグループごとに平均値が異なることを考慮した共通分散を導入してt検定を行った。この方法は2グループの分散が等しいことを前提としている。しかし一般的にいってその前提が適切とは言えない。Studentのt検定は2グループの分散が異なっているデータを用いた際に検定の精度が落ちる。これを「グループ間の分散の違いに対して脆弱である」という。
この脆弱性を克服するべく、グループ間の分散差に頑健性(Robust)を持たせた改良版t検定がWelchのt検定(1938)である。
改良版の分析法というのはもとの分析の原理的な含意を残した上で、ごにょごにょ数学的な調整を掛けて作られている(ことが多い)。その調整がどのようになされているのかを自然言語で理解しようとしても難しい。元の分析の「原理」を理解した上で、実践ではざっくり改良版を使用するのが良い。
分散が異なっている以上、「共通分散」は想定しない。各々の集団の分散をそのまま使う。このままだと有意性が出やすくなる(第一種過誤)ので、その分自由度(等価自由度)で調整する。
- 標準誤差 ← sqrt(グループ1の分散/グループ1のサンプルサイズ + グループ2の分散/グループ2のサンプルサイズ)
- 自由度←標準誤差^4/(グループ1の標準誤差^4/グループ1の自由度 + グループ2の標準誤差^4/グループ2の自由度)
- 検定統計量t ← (グループ1の平均値 - グループ2の平均値) / 標準誤差
- 標準誤差SE
-
グループごとの標準誤差SEは定義通り。
全体の標準誤差はStudentのように共通分散を想定していないので、その代わりにグループごとの分散で計算する。
G H I 1 male female 2 N 244 256 3 df 243 255 4 mean 196.76 175.42 5 u2 2739.00 3475.26 6 SE =SQRT(H5/H2) =SQRT(I5/I2) 11 標準誤差 =SQRT(H5/H2+I5/I2) - 等価自由度
-
式の形こそ美しいが、そこでなにをやっているのやらはさっぱり。
G H I 1 male female 2 N 244 256 3 df 243 255 4 mean 196.76 175.42 5 u2 2739.00 3475.26 6 SE 3.35 3.68 11 標準誤差 4.98 13 自由度 =H11^4/(H6^4/H3+I6^4/I3) - 検定統計量t値
-
G H I 10 平均差 21.34 11 標準誤差 4.98 12 t値 =H10/H11 - p値
-
G H 14 p値(≠) =T.TEST(IF(gender="male",time),IF(gender="female",time),2,3) 15 p値(>) =T.TEST(IF(gender="male",time),IF(gender="female",time),1,3) 16 p値(<) =1-T.TEST(IF(gender="male",time),IF(gender="female",time),1,3) ※T.DIST()関数は自由度が小数の時、小数部を切り捨てる。したがって分析者にとって少し不利な結果が出力される。そのため、p値をダイレクトに求める関数T.TEST()関数を用いる。
- T.TEST()関数
- p値 = T.TEST(集団1の検定変数, 集団2の検定変数,[片側検定…1/両側検定…2],[対…1/Student…2/Welch…3])
結果出力例
| G | H | I | |||
|---|---|---|---|---|---|
| 1 | male | female | |||
| 2 | N | 244 | 256 | ||
| 3 | df | 243 | 255 | ||
| 4 | mean | 196.76 | 175.42 | ||
| 5 | u2 | 2739.00 | 3475.26 | ||
| 6 | SE | 3.35 | 3.68 | ||
| 8 | t検定 | ||||
| 9 | 有意水準 | 5% | |||
| 10 | 平均差 | 21.34 | |||
| 11 | 標準誤差 | 4.98 | |||
| 12 | t値 | 4.29 | |||
| 13 | 自由度 | 495.53 | |||
| 14 | p値(≠) | 0.00 | |||
| 15 | p値(>) | 0.00 | |||
| 16 | p値(<) | 1.00 | |||
| 17 | 信頼上限 | 31.13 | |||
| 18 | 信頼下限 | 11.56 | |||
| 19 | 効果量d | 0.38 | |||
| 20 | 効果量r | 0.19 | |||
主張例
t検定の結果から得られた知見をまとめよ。
-
図表1 B大学学生のジェンダー別スマートフォン利用時間 male female 196.76 175.42 
スマートフォンの利用時間はジェンダーにより差がある。B大学においてスマートフォンの利用時間は男子学生の方が女子学生よりも長い(t(495.53)=4.29, p<.05, d=0.38, r=0.19)。平均利用時間は男子学生196.76分、女子学生175.41分である。
独立した2グループ間での平均の差の検定を行うときには、Student検定ではなく、Welch検定を使用するのが一般的である(cf.Rの場合)。
課題
μ国公立高校では特進コースと一般コースを設置している。公立高校においては高校間よりもコース間によって学力差があるとされている。
全国公立高校の生徒から無作為に200人を抽出し、統一学力試験(100点満点)を行った。本試験は国立大学共通入学テストに準じた内容となっている。この結果から、μ国公立高校の受験学力について、どのような知見が得られるか、述べよ。
| A | B | C | D | E | F | G | H | |||
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | No | class | score | general | special | |||||
| 2 | 1 | general | 62 | N | ||||||
| 3 | 2 | general | 64 | df | ||||||
| 4 | 3 | special | 68 | mean | ||||||
| 5 | 4 | general | 69 | u2 | ||||||
| 6 | 5 | general | 99 | SE | ||||||
| μ国高校生コース別統一学力試験結果データ | ||||||||||
- class(名義尺度)
- B2:B201
- score(比例尺度)
- C2:C201